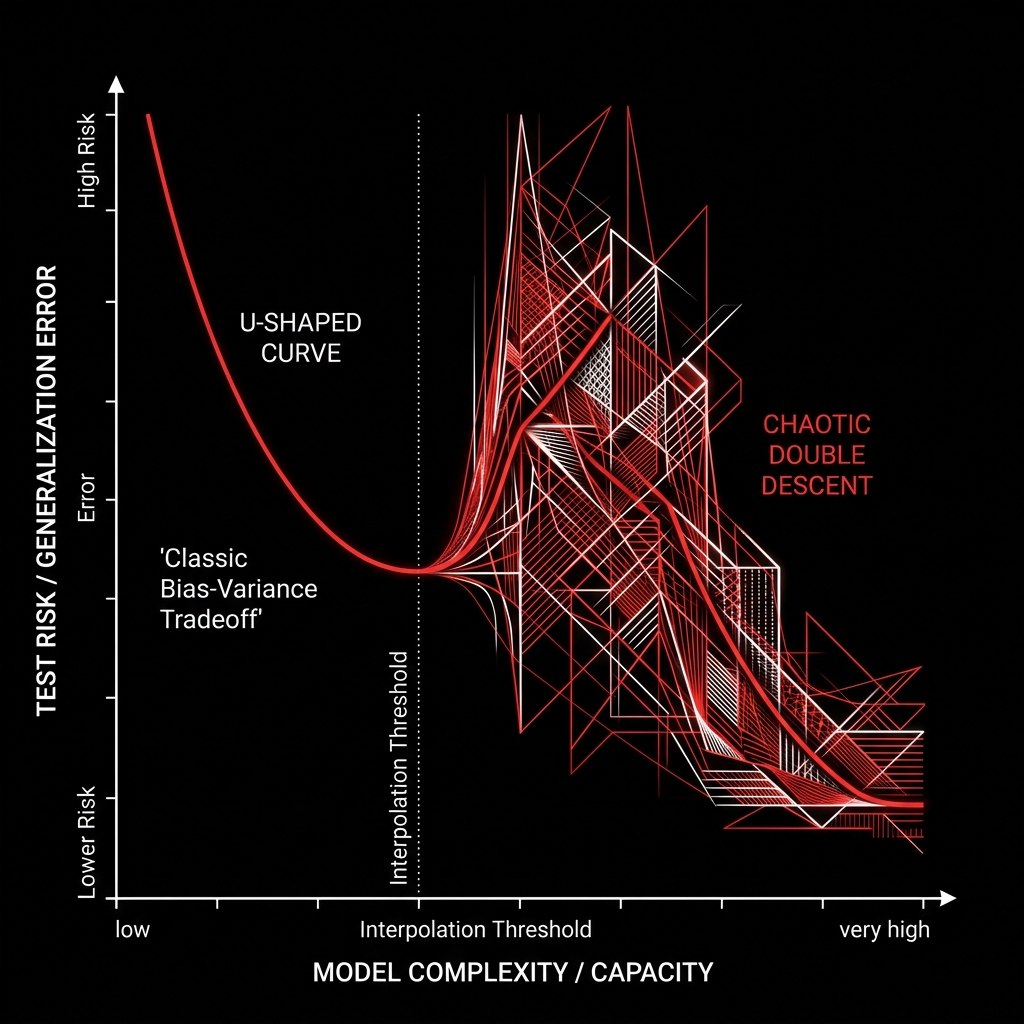
Machine learning models are traditionally evaluated based on their capacity to balance two competing forces: bias and variance. Bias refers to the error introduced by approximating a complex real-world problem with a simpler model, while variance refers to the model's sensitivity to small fluctuations in the training data. For decades, the gold standard for model selection was the U-shaped error curve. The goal was to find the "sweet spot" where a model was complex enough to capture the signal but simple enough to ignore the noise.
According to this classical framework, if a model has too many parameters relative to the amount of data it is training on, it will inevitably overfit. It begins to memorize specific data points-including their random errors-rather than learning the underlying distribution. This leads to a catastrophic drop in performance when the model is tested on new, unseen data. Consequently, engineers have historically been trained to "right-size" their models, carefully pruning complexity to match the scale of the dataset.
However, the rise of massive neural networks has revealed a phenomenon that contradicts this fundamental intuition. We have discovered that if you push past the point of "perfect fit" and continue to add millions or billions of parameters, the error rate does not continue to climb. Instead, it enters a second stage of improvement. This discovery, known as Double Descent, has forced a total re-evaluation of how we understand model capacity and generalization in the age of Deep Learning.
The interpolation threshold represents the most dangerous mathematical zone in machine learning. At the exact moment a model possesses just enough parameters to achieve zero training error, its test error violently spikes. The function it learns fits the training data perfectly while oscillating erratically everywhere else.
The Classical Bias-Variance Tradeoff
To understand why this spike occurs, one must first analyze the classical regime where the number of parameters () is less than the number of data points (). In this zone, the model is under-parameterized. As increases toward , the model's bias decreases because it has more flexibility to fit the data. However, as approaches , the variance explodes. The model is forced to find a function that passes through every single data point, but it has no "extra" parameters to ensure the path between those points is smooth. The resulting function is a high-frequency, jagged line that perfectly hits the training targets but provides nonsensical predictions for anything else.
In traditional statistics, the point where is considered the limit of meaningful learning. Any further increase in parameters was thought to simply provide more ways to fit the noise, leading to even higher variance. Modern research has proven that this limit is actually a temporary peak, not a permanent ceiling.
The Mathematical Constraints of Perfect Fit
Belkin et al. (2019) demonstrated that this interpolation peak shatters classical statistical theory. Traditional guidelines mandate scaling model complexity directly to dataset size to avoid memorizing noise. According to that framework, pushing past a perfect fit guarantees catastrophic failure. In modern deep learning, stopping at this exact optimal theoretical capacity actually traps the architecture at its most brittle state.
Injecting even more parameters forces the model out of this rigid state and into the over-parameterized regime. With massive excess capacity, the geometry of the loss landscape physically changes. Stochastic Gradient Descent's (SGD) implicit bias naturally gravitates toward minimum-norm solutions, discovering a smoother, highly generalized function that classical, properly-sized models physically lack the dimensions to express. In this regime, the model uses its "extra" parameters to find the simplest possible path that satisfies the training data, effectively acting as its own regularizer.
The Role of Label Noise and Epoch Double Descent
The severity of the interpolation peak is directly tied to the quality of the data. Research has shown that "Label Noise"-incorrect or misleading data points in the training set-magnifies the error spike. When a model is forced to interpolate noisy labels with a limited parameter count, it creates massive "oscillations" in the decision boundary to reach those outliers. In an over-parameterized model, the extra dimensions allow the model to "absorb" these noisy points more gracefully, maintaining a smoother global structure.
Furthermore, Double Descent is not limited to model size; it also appears as a function of training time, a phenomenon known as Epoch Double Descent. OpenAI researchers documented that as a model trains, it may reach a point where its test error temporarily increases before dropping again. This occurs because the model often learns the most "jagged" and complex parts of the function mid-way through training. If an engineer stops training during this period, they may inadvertently deploy a model that is stuck in a local generalization trough.
The Regularization Trap
Standard early stopping mechanisms and aggressive regularization techniques often halt training right as the model approaches the interpolation peak. Engineers pull the plug as training error drops to near zero, assuming they have optimized the architecture. In production, these seemingly perfect models collapse under real-world variance. The architecture was abandoned at the precise moment its generalization capacity was at its absolute worst.
The realization that massive scale naturally induces smoother generalization enforces a hard physical floor on system efficiency. If smaller architectures cannot geometrically access these minimum-norm basins, the cost of robust generalization remains permanently tied to hardware bloat. We are trapped in a paradigm where the only way to achieve reliable, smooth intelligence is to build models that are, by classical standards, unnecessarily large.
Belkin et al. (2019) demonstrated that the interpolation threshold forces maximum test error. A second descent occurs only when excess capacity alters the loss landscape.
Frequently Asked Questions
Does double descent always happen?+
Is larger always better then?+
Join the EulerFold community
Track progress and collaborate on courses with students worldwide.
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...