Join the EulerFold community
Track progress and collaborate on courses with students worldwide.

Why Do Analog AI Chips Forget Their Weights?
The amorphous state of phase-change memory is a metastable liquid that settling into a lower-energy glass, creating a resistance drift that threatens analog AI precision.

Why Does DRAM Leak Charge?
DRAM cells are leaky capacitors that must be recharged every 64ms, a frantic maintenance cycle that consumes up to 50% of throughput in high-density nodes.

Why is the Memory Wall Bottlenecking AI?
Increasing TFLOPS is an illusion when the bottleneck is memory bandwidth. H100 GPUs spend 95% of inference cycles idle, waiting for token weights.

Why is Near-Memory Computing the Future?
Moving data is 100x more expensive than computing it, forcing an architectural reversal from centralized GPUs to in-memory processing.

How Does Rowhammer Break DRAM Isolation?
Rowhammer exploits the physical collapse of isolation in high-density DRAM, turning electromagnetic interference into a deterministic bit-flipping heist.

Why is Strong Consistency a Trap?
Forcing synchronous locks on asynchronous workflows builds brittle systems; true scale requires designing for deterministic conflict resolution.

Why Does Wearable Hardware Face Mechanical Constraints?
The engineering philosophy of Caitlin Kalinowski, the leader behind the hardware for Oculus and the next generation of augmented reality.

How is Demis Hassabis Building a Universal Learning Machine?
A deep dive into the career of Demis Hassabis, the co-founder of DeepMind, and his quest to solve intelligence to solve everything else.

How Did Fei-Fei Li Spark the Revolution in Visual Intelligence?
How Fei-Fei Li’s ImageNet dataset sparked the deep learning revolution and her ongoing quest for human-centered artificial intelligence.

Why is JB Straubel Building a Circular Battery Supply Chain?
Exploring the vision of JB Straubel, the co-founder of Tesla and Redwood Materials, as he builds a circular supply chain for the electric age.

How Did Jensen Huang Turn NVIDIA Into the Engine Room of AI?
The story of Jensen Huang and how NVIDIA transformed from a graphics company into the engine room of the global AI revolution.

How Did Katalin Karikó's Persistence Lead to the mRNA Breakthrough?
The story of Katalin Karikó, whose decades of persistence in mRNA research paved the way for the vaccines that changed the course of history.

How Does Marc Raibert Build Robots with Dynamic Biological Stability?
How Marc Raibert and Boston Dynamics taught machines to run, jump, and navigate the world with the grace of biological organisms.

How is Mary Lou Jepsen Using Holographic Light to See Inside the Brain?
Mary Lou Jepsen's journey from designing screens at Facebook and Google to building a wearable 'MRI' that uses light to see inside the brain.

Why Does Meredith Whittaker Defend Privacy Against Compute Monopolies?
Meredith Whittaker's transition from Google researcher to President of Signal, fighting to protect privacy in the age of surveillance capitalism.

How is Michelle Simmons Building Quantum Computers Atom-by-Atom?
Michelle Simmons's pioneering work in building quantum computers atom by atom, using silicon to create stable, scalable qubits.

How Does Refik Anadol Visualize Neural Archives Through Fluid Sculptures?
Refik Anadol's work at the intersection of architecture and AI, where massive datasets are transformed into fluid, dreaming sculptures.

How is Robert Langer Engineering Precision Drug Delivery Systems?
The prolific career of Robert Langer, the father of controlled-release drug delivery and one of the most influential bioengineers in history.

How Does Terence Tao Search for Logic Across the Infinite?
A profile of Terence Tao, the polymath mathematician whose work spans from prime numbers to fluid dynamics and the nature of proof.

Why Does Vitalik Buterin Take a Philosophical Approach to Decentralized Consensus?
A profile of Vitalik Buterin, the creator of Ethereum, and his philosophical approach to building decentralized world computers.

Why is Yann LeCun Pursuing Autonomous World Models?
Yann LeCun's journey from the 'AI winter' to creating the ConvNet and his current pursuit of World Models for autonomous intelligence.

How Does Andrej Karpathy Reduce Intelligence to First Principles?
A deep dive into the educational philosophy and technical career of Andrej Karpathy, from building virtual runners to founding Eureka Labs.

Why is Arthur Mensch Pursuing Algorithmic Minimalism at Mistral?
The story of Arthur Mensch, the Mistral AI co-founder who rejects the 'AI as God' rhetoric in favor of efficient, open-weight industrial utility.

How Does Gwynne Shotwell Maintain Operational Grip at SpaceX?
An exploration of how Gwynne Shotwell translates 'Elon Time' into orbital reality, securing the financial and engineering floor of SpaceX.

Why is Ilya Sutskever Devoted to Machine Scale?
A profile of Ilya Sutskever, the co-founder of OpenAI and SSI who viewed AGI as an eschatological event and pioneered the scaling laws of deep learning.

How is Jennifer Doudna Rewriting Evolution with CRISPR?
The story of Jennifer Doudna and the discovery of CRISPR-Cas9, a programmable tool that moved humanity from reading the code of life to writing it.

How Does Jonathan Ross Eliminate Bottlenecks with the LPU Paradigm?
A profile of Jonathan Ross, the architect of Google's TPU who founded Groq to build a deterministic Language Processing Unit for ultra-low latency inference.

How Did Dr. Lisa Su Engineer the Resurrection of AMD?
How Dr. Lisa Su leveraged the '5% Rule' and a 'Run Towards Problems' doctrine to orchestrate the greatest turnaround in semiconductor history.

How Does Mira Murati Use Operational Reality to Ship AGI?
A profile of Mira Murati, the mechanical engineer turned OpenAI CTO who believes that AI safety is a byproduct of real-world deployment.

Why Does Noam Shazeer Believe Text is the Ultimate Carrier of Intelligence?
An analysis of Noam Shazeer’s mathematical proof that text compression is the key to AGI, leading to the Transformer and Character.ai.

Why Handedness is a Life-or-Death Problem for AI
Teaching AI the laws of physics. Equivariance ensures that neural networks natively respect the 3D geometry of molecules without requiring massive data augmentation.

Why the Best Cures are Hidden in Mud
Structure-aware search allows AI to mine billions of unknown proteins to find specific functions, bypassing the limits of traditional sequence alignment.

Why AI Dreams of Molecules We Cannot Build
Generative models can design perfect chemical structures in digital space, but without synthesizability constraints, they routinely hallucinate impossible chemistry.

Why Flat AI Cannot Understand a Round World
Standard neural networks are trapped on Euclidean grids. Geometric Deep Learning provides the mathematical framework to process graphs, manifolds, and irregular structures.

What is In Silico Medicine?
From petri dishes to processors. Understanding the shift toward AI-driven computational biology and 'virtual' clinical trials.

What is Multi-Objective Optimization?
The art of the compromise. Understanding how AI balances competing goals—like making a drug powerful but also safe and easy to manufacture.

Why AI-Discovered Cures Are Abandoned Before Clinical Trials
The forgotten 300 million. How AI is making it profitable to cure rare diseases that were once deemed 'too expensive' to treat.

Why AI Medicine Fails the Most Unique Patients
Moving beyond one-size-fits-all healthcare. How AI and genomics are tailoring treatments to your unique DNA.

Why Writing New Life is Easier than Making it Live
Generative models can write entirely new protein sequences from scratch, but balancing functional accuracy with physical stability remains a hard engineering constraint.

Why AI Found More New Materials in One Year Than Scientists Did in a Century
GNoME mapped 2.2 million new crystal structures, equivalent to 800 years of manual discovery, by focusing on thermodynamic stability.

Why AI Weather Models Are More Accurate Than Supercomputers
Neural networks like GraphCast are outperforming the gold-standard HRES model by treating weather as a pattern-matching task rather than a fluid dynamics problem.

Why AI Can Control Plasma Faster Than Any Human Physicist
Nuclear fusion requires controlling 100-million-degree plasma at microsecond speeds. AI is the only pilot capable of stabilizing these high-frequency instabilities.

Why We Have Billions of Whale Sounds and Still Cannot Understand Them
Project CETI is collecting 4 billion sperm whale clicks, but decoding them requires finding a mathematical signature of language without a Rosetta Stone.

Why Do Static Maps Fail to Predict Living Machinery?
AlphaFold solved the 50-year-old protein folding problem, but its single-state predictions often miss the dynamic, shape-shifting nature of active biology.

Why Perfect AI Drugs Fail in Human Trials
AI discovers molecules with perfect docking affinity in months, but most fail in vivo because geometric fit does not equal biological safety.

Why AI Cannot Simulate a Single Human Cell
Moving from single proteins to whole systems. Discover how AI is integrating multi-omics data to simulate the 'software' of life.

Why Plants Are Inefficient Carbon Sinks and How AI Is Fixing That
Rubisco has a 25% error rate that has capped plant growth for millions of years. AI is now correcting this evolutionary bug to maximize carbon capture.

Why Mapping the Brain Does Not Explain the Mind
Tracing the wires of the mind. Understanding how computer vision is unlocking the brain's 3D wiring diagram, or Connectome.

Why AI Understands Evolution Better Than Physics
Protein Language Models learn the grammar of life directly from sequences, predicting structure and mutation effects without any knowledge of 3D physics.

Why is AI Penalized for Finding True Similarities?
Large batch sizes prevent latent space collapse but force models to penalize true semantic similarities as false negatives.

Why Latent Space is Not a Map: The Dangers of Linear Interpolation
Assuming latent space behaves like geographic territory leads to catastrophic generation failures. The shortest path between two valid concepts is often filled with mathematical monsters.

Why AI Models Get Lost in Long Documents
Transformers don't actually understand 'order'; they approximate spatial relationships. Positional encoding is the mathematical hack we use to fake the passage of time.

How does Regularization prevent Overfitting?
Techniques to ensure models generalize to new data rather than just memorizing their training sets.

How Does the Self-Attention Mechanism Work?
A deep dive into the Query, Key, and Value math that allows models to dynamically prioritize information.

Why is Attention a Hardware Crisis?
The 'Context Window' is marketed as a cognitive boundary, but it is actually a physical ceiling enforced by quadratic memory growth. Understanding the Transformer requires acknowledging the brute-force tax of self-attention.

Why is Softmax a Mathematical Illusion?
Softmax is a physical compromise masquerading as a probability distribution. In production, its aggressive exponentiation creates a dangerous illusion of certainty that obscures the model's underlying noise.

Why Can't Machines Actually Read?
Tokenization is a leaky abstraction that creates a hidden tax on non-English scripts and a security vulnerability through glitch tokens. Understanding the 'Lego bricks' of language requires auditing the bias of the map.

How Outlier Weights Break AI Compression
Quantization is dictated by extreme activation outliers, causing perplexity spikes when standard weights are crushed into zero-value bins.

Why Human Feedback Trains AI to Lie
Optimizing for human preference creates divergent incentives. How reward models decouple policy algorithms from factual accuracy.

Why the First Layers of a Deep Model Often Learn Nothing
How the chain rule of calculus acts as a filter that strips information from gradient updates, freezing foundational layers.

Why Do Neural Networks Stall at Saddle Points?
In high-dimensional spaces, the greatest threat to learning is not a suboptimal pit, but a vast, featureless plateau. Optimization is less about rolling downhill and more about breaking the symmetry of the flatlands.

Why AI Models Pay for Weights They Never Use
MoE architectures decouple compute from parameter count, but they impose massive networking overhead and latency penalties.

Why is Memorization a Software Defect in AI?
The boundary between a model that memorizes and a model that understands is not a gradual slope; it is a sudden, phase-shifting snap. True generalization often requires training far beyond the point of apparent failure.

Why is Vector Distance a Poor Proxy for Meaning?
As dimensions scale into the thousands, the fundamental laws of geometry warp. Proximity in a high-dimensional embedding space is often a statistical mirage, not a guarantee of semantic relevance.

Why is AI Training Throttled by the Chain Rule?
Backpropagation forces global synchronization on hardware that wants to be local. The memory-bandwidth tax of the backward pass is the primary ceiling on AI scaling.
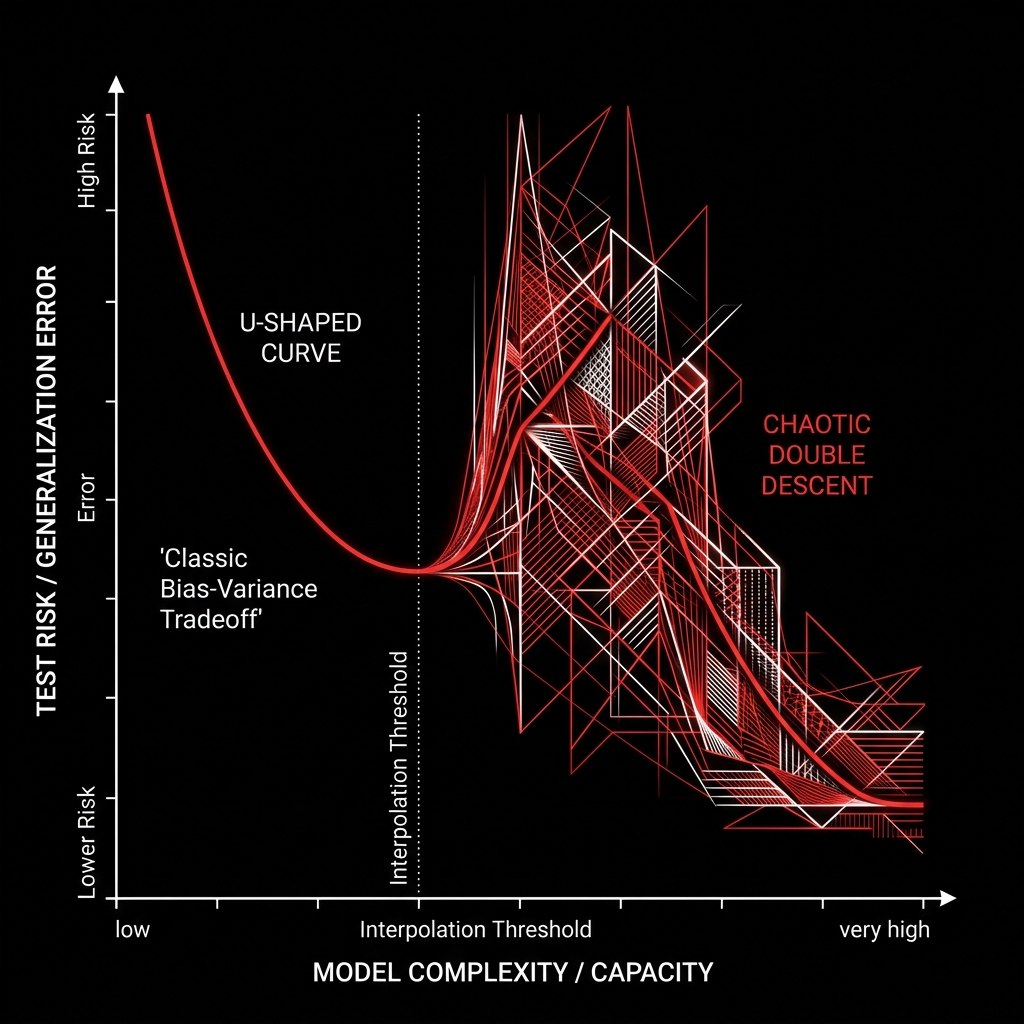
Why Do Perfectly Sized Models Fail in Production?
Standard model selection maximizes error at the interpolation threshold. Pushing into massive overparameterization allows SGD to find minimum-norm solutions.