Gemini Team, Google (2023)
Gemini: The First Truly Multimodal Foundation
In late 2023, Google introduced Gemini, a family of models designed to be natively multimodal from the beginning of their training. Many previous multimodal systems relied on separate vision and language components that were connected after their initial training, but Gemini was trained simultaneously across text, images, audio, video, and code. This integrated architecture allows the model to reason across different types of information with a level of fluidity that more closely resembles human perception. This represents a shift away from modular multimodality toward a system that treats all data types as primary inputs.
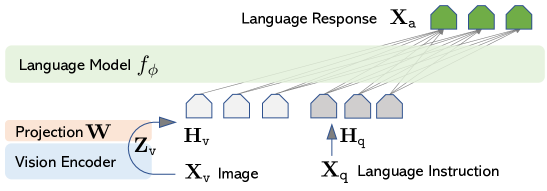
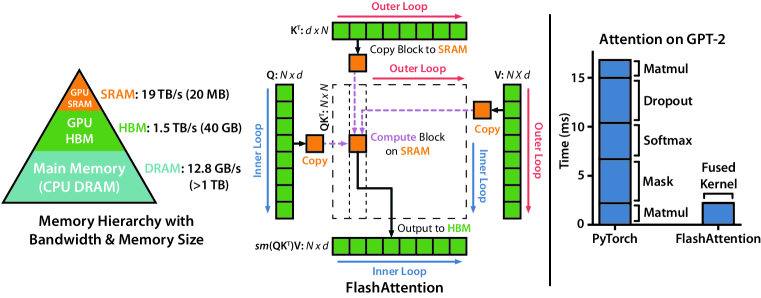
The architecture is built on a transformer-based decoder that interleaves visual patches, audio samples, and text tokens into a unified sequence. This enables cross-modal self-attention across every layer of the model's backbone, allowing for complex reasoning tasks such as explaining physics diagrams or interpreting live video feeds. This native integration bypasses the bottlenecks often created when diverse data types are forced through separate linguistic or visual encoders. The result is a single reasoning engine that can attend to the raw complexity of different data streams in their original form.
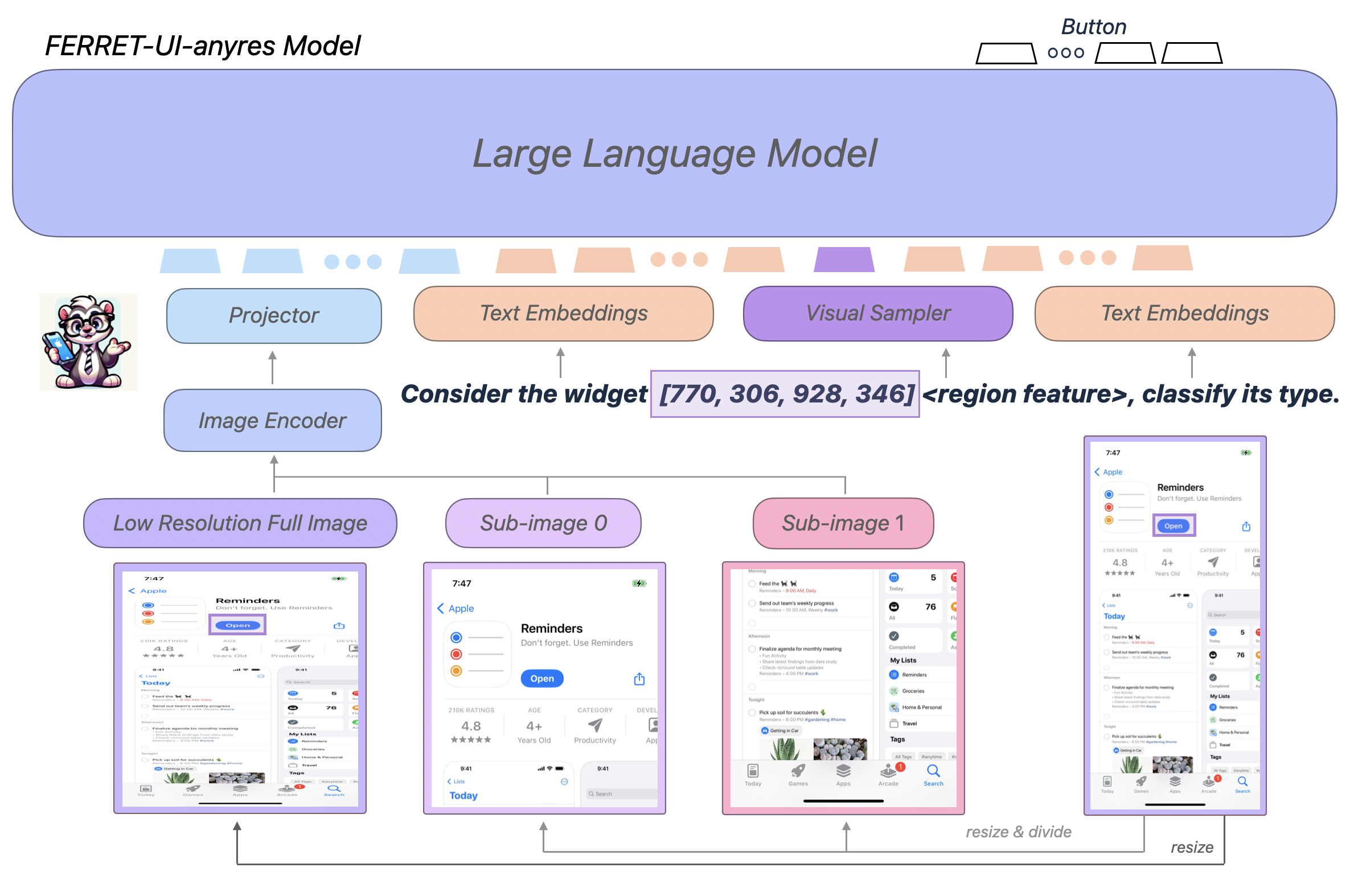
A sophisticated tokenization process is used to achieve this integration. Visual data is handled with a variable-resolution approach that preserves aspect ratios and fine-grained details, while audio is converted into tokens using a neural mapper sampled at 16kHz. Video is processed as a series of image frames interleaved with precise timestamps, ensuring that both temporal dynamics and spatial relationships are maintained. By treating a visual event and its textual description as equivalent units of information, the model can reason across domains more effectively. This suggests that the most efficient architectures ingest sensory data directly rather than translating it into text first.
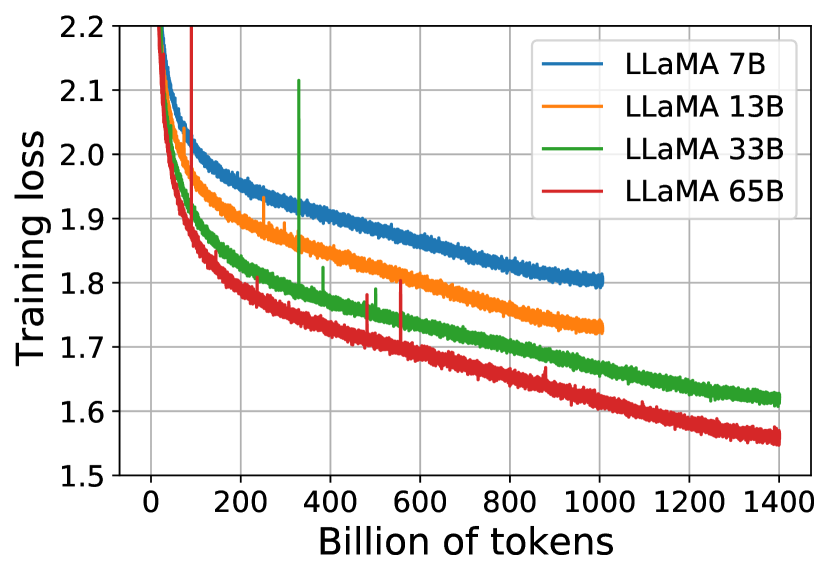
The training of Gemini required substantial leaps in infrastructure, utilizing custom TPUv4 and TPUv5e accelerators across multiple data centers. Trillions of tokens and billions of parameters were managed through a combination of model, data, and pipeline parallelism to minimize communication overhead. Maintaining hardware reliability at this scale is a critical challenge, and Google developed automated recovery systems to handle silent data corruption and chip failures. This engineering effort ensured that the training process remained stable over months of operation, proving that foundation models are as much a feat of systems engineering as they are of machine learning logic.
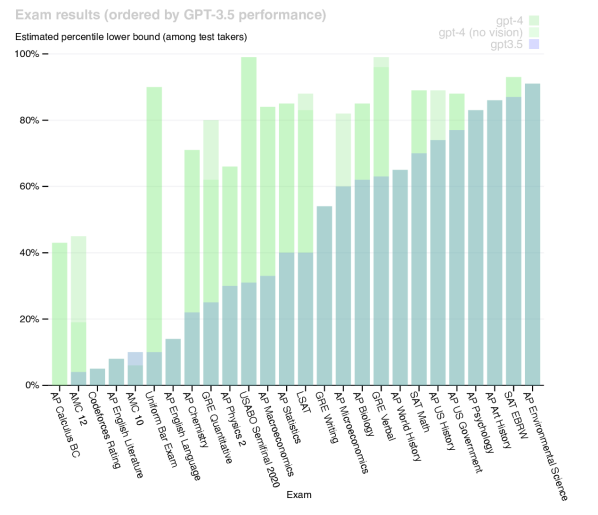
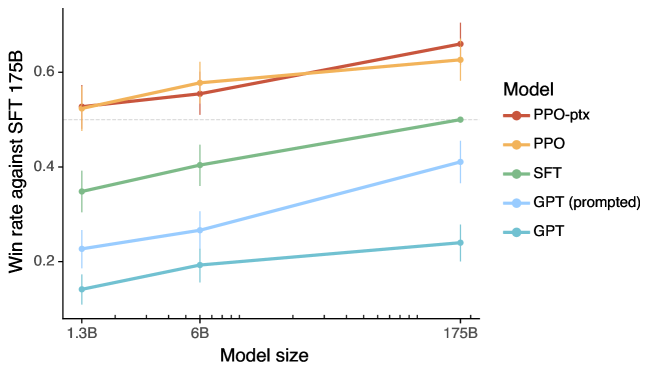
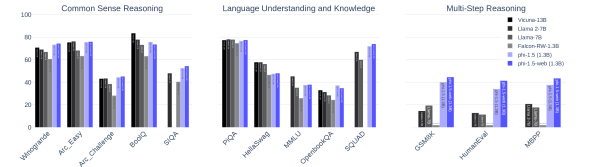
The reasoning performance of Gemini Ultra on benchmarks like MMLU suggests that native multimodality enhances capability on tasks requiring combined visual and logical reasoning. The model's ability to interpret a chart and then write code to reproduce it demonstrate cross-modal reasoning that exceeds the capacity of modular systems. This suggests that the future of AI development may lie in deeper integration of sensory inputs rather than just increasing model size. As systems become more holistically perceptive, the challenge will be to further refine how they interact with the physical world.