The QLoRA Breakthrough: AI for Everyone
Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2023). QLoRA: Efficient Finetuning of Quantized LLMs. arXiv:2305.14314.
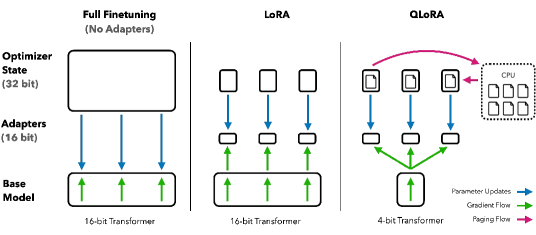
The 2023 QLoRA paper from the University of Washington significantly lowered the cost of fine-tuning massive language models. Previously, adapting a 65-billion parameter model required nearly 800 gigabytes of video memory, a requirement that restricted the task to high-performance computing clusters. Researchers proposed a method for fine-tuning 4-bit quantized models without sacrificing performance. This development allows for the adaptation of state-of-the-art models on a single professional GPU, demonstrating that high-precision memory is not a prerequisite for effective learning in neural networks.
The core of the framework is the 4-bit NormalFloat data type, which is designed to be information-theoretically optimal for the normal distribution of model weights. This is combined with double quantization to compress the quantization constants and paged optimizers that manage memory spikes by offloading data to the CPU. Together, these techniques reduce the memory requirements of a 65-billion parameter model by approximately ninety percent. This shift proves that the hardware barrier to AI research can be mitigated through software optimizations that manage information flow more effectively.
Double quantization saves additional memory by treating the scaling constants from the first round of quantization as data and quantizing them again. Simultaneously, paged optimizers act as a pressure-relief valve for the GPU, moving data to system RAM when necessary. This reveals that memory limits in AI are often dynamic processes that can be managed through intelligent paging strategies. By transforming GPU memory into a rolling buffer of gradients, the researchers proved that hardware constraints are frequently the result of software that is not fully optimized.
The performance of the Guanaco models, which achieved over ninety-nine percent of ChatGPT's capabilities on a single GPU, suggests that the barrier to high-level AI is primarily one of efficiency. Independent researchers can now compete with large-scale industrial labs by using more surgical adaptation techniques. This raises questions about the long-term necessity of massive computational clusters for model refinement. The focus of the industry is shifting from increasing memory usage to managing it more precisely during the model lifecycle.
As quantization techniques become more integrated into the model development process, the economics of AI deployment will continue to change. The ability to fine-tune large models on consumer-grade hardware accelerates the development of specialized applications across various fields. The principles of QLoRA suggest that the future of the field will be defined by models that use memory surgically to maintain their learning capacity. This democratization of technology ensures that advanced AI capability is no longer the exclusive domain of those with the largest infrastructure.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
QLoRA Paper on arXiv
arXiv • article
Explore ResourceGitHub Implementation
GitHub • code
Explore ResourceHugging Face Blog
Hugging Face • article
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.