Teaching Computers the Meaning of Words
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems, 26.
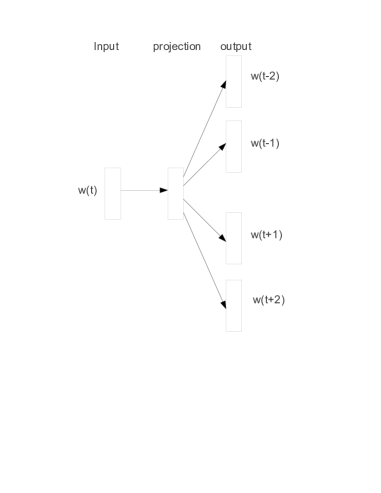
In 2013, Tomas Mikolov and colleagues at Google introduced a method for mapping human language into a continuous geometric space, replacing discrete symbolic indices with dense, high-dimensional vectors. Prior to this research, words were represented as atomic units that lacked any mathematical relationship to one another. The researchers demonstrated that by training shallow neural networks to predict the context of a target word, individual tokens can be positioned in a coordinate system where geometric proximity correlates with semantic similarity. This shift enabled computers to perform algebraic operations on concepts, effectively digitalizing the relational structure of natural language.
Skip-gram Architecture and Negative Sampling

The core technical mechanism of Word2Vec is the Skip-gram architecture, which optimizes word embeddings by maximizing the probability of predicting surrounding words given a central token. To make this process computationally feasible on datasets containing billions of words, the researchers implemented negative sampling - a technique that replaces the expensive updates of the entire vocabulary with a small set of randomly selected noise examples for each training step. This methodological choice reduced the training time to a fraction of that required by previous neural language models. It established that the meaning of a word can be accurately reconstructed through a local, predictive task, revealing that the statistical regularities of context provide a sufficient signal for the autonomous learning of semantic structure.
Linear Relationality and Vector Arithmetic
A critical finding of the research was the emergence of linear relationality, where consistent semantic relationships are represented by constant vector offsets. The discovery that the relationship between "Man" and "Woman" is geometrically parallel to the relationship between "King" and "Queen" proved that the model had autonomously identified gender as a specific direction in the vector space. This property extended to diverse categories, including geographic locations, verb tenses, and pluralization. This finding demonstrated that human language possesses an underlying topological structure that can be captured as a set of linear transformations. It suggested that complex logical concepts are encoded as stable geometric relationships within the latent representation of data.
Phrase Compositionality and Tokenization
The researchers addressed the limitation of treating every word as an individual unit by introducing a data-driven approach to identify phrase compositionality. By evaluating the frequency of word pairs relative to their individual occurrences, the system could identify tokens like "Air_Canada" or "Boston_Globe" as single entities rather than collections of independent words. This engineering choice prevented the dilution of specific meanings into general-purpose components, ensuring that the resulting vector space reflected the idiomatic and structural nuances of actual usage. This revealed that the most effective way to represent meaning is to treat high-information word combinations as distinct primitives in the geometric map.
Scalability and Data-Centric Machine Learning
The ability to train Word2Vec on massive corpora in a single day demonstrated that the progress of language understanding is primarily driven by computational efficiency and data scale. In addition to negative sampling, the use of subsampling for frequent, low-information words like "the" or "in" allowed the model to prioritize the rare tokens that define a sentence’s semantic intent. This engineering shift moved the field toward a data-centric paradigm, where the architecture of the model is simplified to facilitate the processing of unprecedented volumes of information. It established the principle that a sufficiently large collection of simple local observations can yield a robust and global understanding of complex conceptual systems.
The Limits of Static Semantic Mapping
While Word2Vec provided a precise mathematical map of language usage, the reliance on a static coordinate system introduces specific technical constraints. A fixed vector space captures the average meaning of a word over a corpus but lacks the dynamic capacity to adapt to the shifting intents of real-time communication. The proximity between vectors identifies similarity in usage rather than a genuine understanding of logical causality or intent. This leaves open the question of whether the fluid nature of human expression can be fully captured by a rigid geometric structure, or if more advanced representations must be developed that can reshape themselves in response to the specific context of an interaction.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Distributed Representations (Official Paper)
arXiv • article
Explore ResourceThe Illustrated Word2Vec (Jay Alammar)
Blog • article
Explore ResourceWord2Vec Archive (Google)
Google • docs
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.