The Simple Trick That Made Deep Learning Scale
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: a simple way to prevent neural networks from overfitting. Journal of Machine Learning Research (JMLR), 15(1), 1929-1958.

In 2012, Geoffrey Hinton and colleagues introduced Dropout, a stochastic regularization technique that addresses the problem of overfitting in high-capacity neural networks. Prior to this research, large models frequently exhibited a significant generalization gap, achieving high accuracy on training data while remaining fragile when presented with unseen examples. The researchers demonstrated that by randomly omitting a subset of neurons during the training process, a network is forced to learn redundant and robust representations, effectively preventing the development of complex co-adaptations where neurons rely on specific partners to compensate for their errors. This finding established that the stability of a neural system can be enhanced by introducing structural uncertainty into its internal state transitions.
Stochastic Neuron Omission and Internal Redundancy
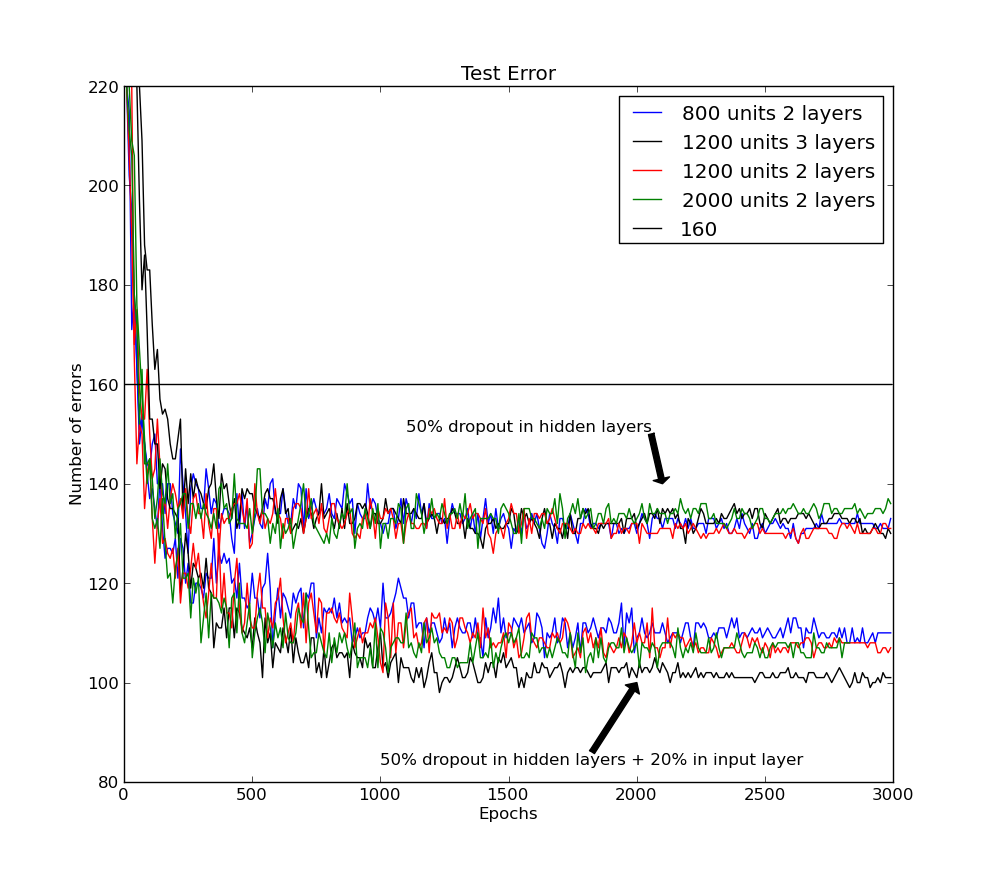
The core technical mechanism of Dropout is the random deletion of hidden units and their incoming and outgoing connections during each training iteration. For each mini-batch, each neuron is independently preserved with a fixed probability , typically set to 0.5. This methodological choice forces the network to operate as a different, "thinned" sub-architecture for every update. This finding revealed that the most effective way to prevent overfitting is to ensure that no individual neuron can rely on the presence of another specific neuron to identify a feature. By making the survival of any single node unpredictable, the system learns a distributed representation where the "intelligence" of the network is not localized but is instead an emergent property of many independent, robust feature detectors.
Breaking Co-adaptations and Feature Interpretablity
A critical technical detail identified in the research was the emergence of cleaner, more interpretable feature detectors in models trained with Dropout. Without regularization, neurons often form complex co-adaptations that target the noise in the training set, leading to noisy and non-interpretable weight patterns. Dropout breaks these dependencies, forcing early layers to identify distinct, reliable signals such as specific edges or textures. This finding established the "mixability" of features as a metric for model robustness, suggesting that the most resilient architectures are those where any subset of components can cooperate to produce a valid output. It revealed that the bottleneck in generalization was the tendency of backpropagation to find narrow, fragile pathways through the parameter space that are highly sensitive to specific data configurations.
Model Averaging and Inference Scaling
The researchers provided a technical justification for Dropout as an efficient approximation of Bayesian model averaging. Training with Dropout is equivalent to simultaneously optimizing a collection of different architectures that share the same underlying weights. At test time, the weights are scaled by the dropout probability to simulate the combined output of this massive ensemble within a single forward pass. This application demonstrated that the benefits of model ensembling can be achieved without the linear increase in computational cost associated with training and storing multiple independent networks. This finding digitalized the logic of consensus-based prediction, proving that the average behavior of many randomized sub-networks is more reliable than the behavior of any single deterministic architecture.
Impact on Large-Scale Model Training
The practical significance of Dropout is evidenced by its widespread adoption in vision, speech, and natural language processing tasks. By providing a computationally simple yet theoretically robust method for preventing overfitting, the technology facilitated the training of deeper and wider models that were previously prone to immediate saturation. The success of this method proved that the scalability of artificial intelligence is determined by the system's ability to maintain structural flexibility during the optimization phase. This realization remains the central theme of research into dropout variants, including spatial dropout for convolutional networks and variational dropout for recurrent models, which seek to adapt the principle of stochastic omission to specialized architectural constraints.
The Logic of Systematic Information Loss
The achievement of Dropout demonstrated that the efficiency of a learning system is often improved by the strategic introduction of information loss. The decision to deliberately weaken the network during training revealed that the primary constraint on high-dimensional learning was the tendency for systems to memorize rather than generalize. This principle remains central to the design of modern regularizers and data augmentation strategies, suggesting that the most robust way to extract truth from data is to ensure that the learning process is immune to the removal of its individual parts. It leaves open the question of whether there exists a purely deterministic optimization objective that can achieve the same level of robustness without the stochastic overhead of neuron omission.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Dropout: A Simple Way to Prevent Overfitting (Official JMLR)
JMLR • docs
Explore ResourceDropout Paper (arXiv Preprint)
arXiv • article
Explore ResourceA Visual Guide to Dropout Regularization
Towards Data Science • article
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.