The Predictable Intelligence of Scaling
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., ... & Amodei, D. (2020). Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
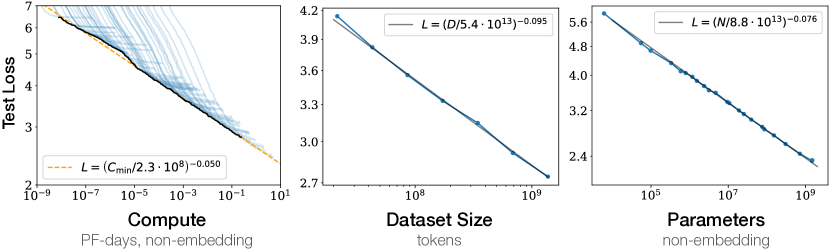
In 2020, researchers at OpenAI established that the performance of large language models follows a predictable power-law relationship with three primary variables: the number of non-embedding parameters, the size of the training dataset, and the total amount of compute used for optimization. This research transitioned the development of neural architectures from heuristic experimentation toward a rigorous engineering discipline, demonstrating that cross-entropy loss improves smoothly over seven orders of magnitude as these factors are increased. The findings revealed that the efficiency of language modeling is a structural property of scale, allowing for the precise prediction of the behavior of massive models through small-scale experimentation.
Power-Law Relationships and Performance Predictability
The primary technical discovery of the paper is the identification of universal scaling curves that remain stable across diverse Transformer architectures. The researchers proved that when a model is not bottlenecked by any single factor, its loss scales as , , and , where is parameter count, is dataset size, and is training compute. A critical nuance of this finding was the exclusion of embedding parameters from the scaling calculations, which revealed that the core attentive blocks obey a consistent mathematical logic regardless of vocabulary size. This discovery established that the "intelligence" captured by a model is a function of its total capacity to process relational data rather than the specific way that capacity is partitioned within the architecture.
The Compute-Efficient Frontier and Sample Efficiency
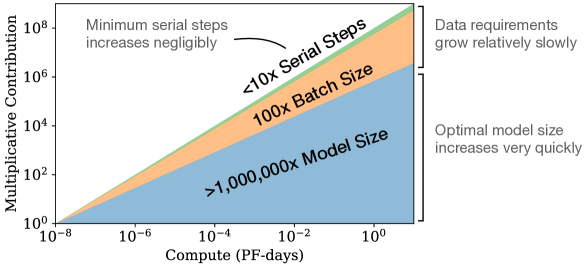
The research defined the compute-efficient frontier, identifying the optimal tradeoff between model size and data volume for a fixed computational budget. Kaplan et al. demonstrated that for a given amount of training compute, the most effective strategy is to train significantly larger models on relatively modest amounts of data and stop training well before full convergence. This contradicted the earlier assumption that maximizing data volume was the primary requirement for large-scale learning. The findings revealed that larger models are fundamentally more sample-efficient, achieving a lower loss using fewer total tokens compared to smaller models. This principle allowed researchers to optimize training schedules by aligning model capacity with the available compute budget.
Architectural Independence and Parameter Count
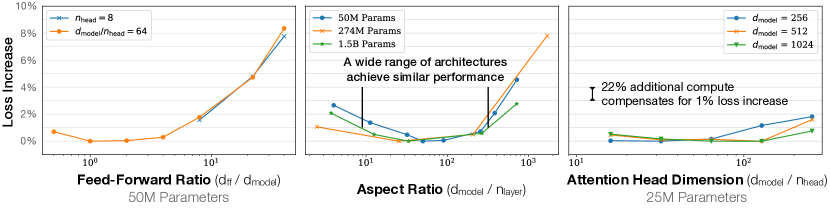
A critical technical detail established by the researchers is the near-total independence of model performance from specific architectural hyperparameters, such as the ratio of depth to width or the number of attention heads. Within a broad range, a shallow and wide model performs almost identically to a deep and narrow one if they share the same total parameter count. This finding simplified the design process by proving that there is no "perfect" architectural shape that must be discovered through exhaustive search. The result shifted the focus of machine learning research from architectural tuning to the systematic management of scale, establishing the total number of non-embedding parameters as the definitive metric of a model's potential utility.
Scaling Limits and the Data Bottleneck
Despite the predictability of these laws, the research identified specific thresholds where the scaling of individual factors begins to provide diminishing returns. As models reach extreme scales, the statistical structure of the underlying data distribution becomes the primary bottleneck, potentially leading to a saturation of performance. The researchers noted that these laws are highly sensitive to the precise measurement of exponents and may be influenced by the quality and diversity of the training tokens. This leaves open the question of whether the informational density of natural language possesses an absolute limit that cannot be resolved through additional compute, or if new architectural primitives can shift the scaling exponents toward higher levels of efficiency.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Scaling Laws (Official arXiv)
arXiv • article
Explore ResourceScaling Laws for Neural Language Models (OpenAI Blog)
OpenAI • article
Explore ResourceScaling Laws and the Compute Frontier (Video)
YouTube • video
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.