Transformers with an Infinite Memory Span
Dai, Z., Yang, Z., Yang, Y., Carbonell, J., Le, Q. V., & Salakhutdinov, R. (2019). Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860.
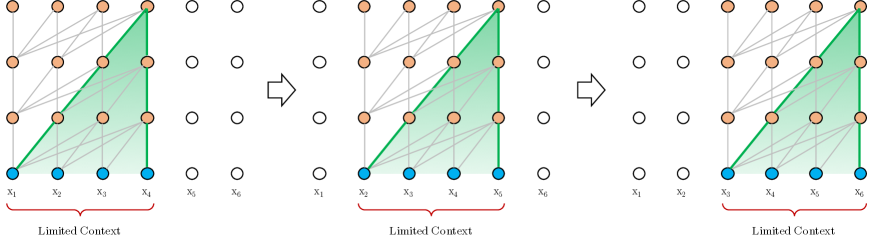
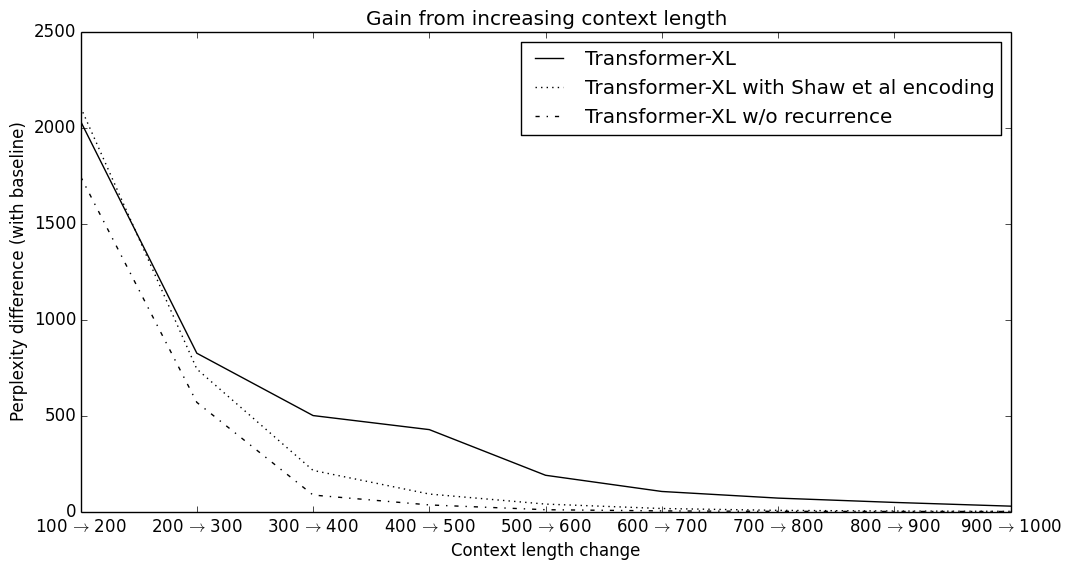
In 2019, researchers at Google Brain and Carnegie Mellon University introduced Transformer-XL, an architecture designed to capture long-range dependencies beyond the constraints of a fixed-length context window. Standard Transformers process input in isolated segments, leading to context fragmentation where the model lacks access to information from preceding blocks. The researchers demonstrated that by integrating segment-level recurrence and a relative positional encoding scheme, a model can model dependencies that are 450% longer than vanilla Transformers while increasing evaluation speed by over 1,800 times.
Segment-Level Recurrence and State Caching
The primary technical contribution of the paper is the implementation of segment-level recurrence. In this framework, the hidden states computed for the previous segment are cached and utilized as an extended context for the current segment. During the forward pass, the attention mechanism for each layer integrates both the local hidden states and the frozen states from the preceding block. This mechanism allows the information to propagate across segment boundaries, effectively creating a temporal memory that spans multiple computational windows. This methodological choice proved that the modeling of long-range relationships is a function of state reuse rather than the absolute size of the training segment.
Relative Positional Encoding and Temporal Bias

To facilitate the reuse of hidden states across segments, the researchers introduced a relative positional encoding scheme. Standard positional encodings are tied to absolute indices, causing the model to lose temporal coherence when hidden states from a previous segment are shifted into the current window. The new scheme instead encodes the distance between tokens, ensuring that the attention bias remains consistent regardless of the segment's starting point. This finding demonstrated that a model's perception of sequence structure can be made invariant to absolute coordinates, allowing the attention mechanism to generalize to sequences significantly longer than those encountered during the training phase.
Impact on Modeling Efficiency and Coherence
The technical significance of Transformer-XL is evidenced by its performance on large-scale language modeling benchmarks such as WikiText-103 and enwik8. By capturing dependencies spanning thousands of tokens, the architecture achieves a higher degree of narrative coherence compared to models restricted by rigid context windows. Furthermore, the recurrence mechanism eliminates the need for redundant computations during evaluation, as the model does not need to re-process overlapping segments to predict the next token. This application proved that the scalability of language models is determined by the efficiency of their memory management strategy.
Contextual Scaling as an Architectural Primitive
The success of this research established that the management of temporal state is a primary constraint on the capacity of attentive systems. The decision to implement recurrence within the Transformer framework revealed that the bottleneck in sequence modeling was the structural isolation of information blocks. This principle remains central to the development of modern context-scaling techniques, including the large-context windows found in foundation models like Gemini and GPT-4. It leaves open the question of how these recurrent mechanisms can be optimized for sub-quadratic complexity or if there exists a fundamental threshold where memory compression becomes a prerequisite for further expansion.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Transformer-XL (Official arXiv)
arXiv • article
Explore ResourceAttentive Language Models (Google Research Blog)
Google • article
Explore ResourceGitHub: Transformer-XL Code
GitHub • code
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.