The Paper That Taught AI the Context of Words
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
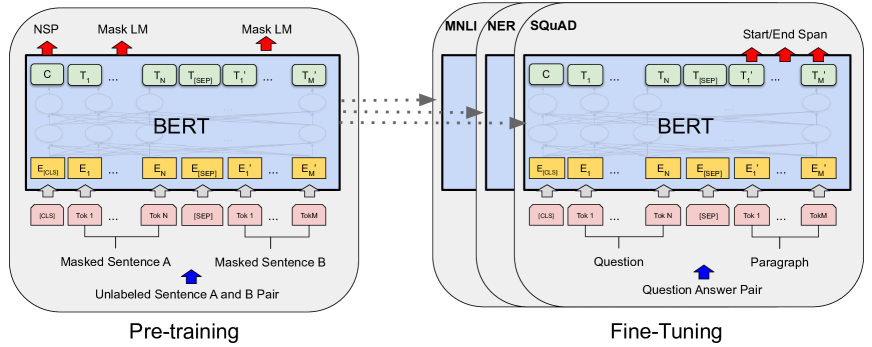
In 2018, researchers at Google AI introduced BERT (Bidirectional Encoder Representations from Transformers), an architecture designed to fuse context from both directions simultaneously across all layers of a language model. Prior to this research, standard language models were either unidirectional, processing text from left to right, or used shallow concatenations of independent forward and backward passes. The researchers demonstrated that by utilizing a masked language modeling objective, a Transformer encoder can be pre-trained to capture the nuanced, inter-dependent relationships within a sequence, establishing a new paradigm for natural language understanding and transfer learning.
Masked Language Modeling and Joint Context
The primary technical contribution of the BERT framework is the Masked Language Modeling (MLM) pre-training objective. In this task, 15% of the input tokens are randomly selected for potential masking. The model is then trained to predict the original identities of these masked tokens using only the unmasked context. This methodological choice allows the model to develop a deep, bidirectional representation where every token in every layer is conditioned on the entire sequence. This finding proved that the ability of a model to resolve semantic ambiguities - such as the meaning of a word that depends on later clauses in a sentence - is significantly enhanced when the restriction of autoregressive, left-to-right processing is removed.
The 80/10/10 Masking Heuristic and Robustness
To address the discrepancy between pre-training (where the [MASK] token is present) and fine-tuning (where it is not), the researchers implemented a specific masking strategy. Of the 15% of tokens chosen for prediction, 80% are replaced with the [MASK] token, 10% are replaced with a random word from the vocabulary, and 10% remain unchanged. This approach forces the model to maintain a robust contextual representation for every input token, as the system cannot assume that a given token is correct or has been corrupted. This finding revealed that the reliability of a language model's internal states is determined by the amount of structural uncertainty introduced during the learning phase.
Next Sentence Prediction and Discourse Coherence
BERT utilizes a second pre-training objective termed Next Sentence Prediction (NSP) to capture relationships between distinct sentences. The model is presented with pairs of sentences (A and B) and must determine if B is the actual sequence that follows A in the original corpus. This binary classification task enables the model to identify discourse relationships and linguistic coherence, providing the foundational knowledge required for downstream tasks such as question answering and natural language inference. The success of this objective demonstrated that language understanding requires not only local token-level context but also a global understanding of how information is structured across multiple sentences.
Unified Embedding Architecture and Input Representation
The input representation in BERT is a structured summation of three independent embedding layers: token, segment, and position embeddings. Token embeddings handle sub-word units using the WordPiece vocabulary, while segment embeddings explicitly differentiate between the first and second sentences in a pair. Position embeddings provide the necessary spatial information for the permutation-invariant Transformer blocks. By summing these vectors, BERT creates a high-dimensional signal that carries the identity, context, and structural role of every token. This findng showed that a unified input representation is sufficient for the self-attention heads to compute complex relational data without the need for task-specific architectural modifications.
The Pre-train and Fine-tune Paradigm
The practical significance of BERT lies in its ability to be adapted to a wide range of natural language tasks with minimal modification. By adding a single output layer on top of the pre-trained encoder, researchers can achieve state-of-the-art results on classification, sequence labeling, and question-answering tasks. This application established the "pre-train then fine-tune" workflow as the standard methodology for NLP, shifting the engineering focus from the design of specialized architectures to the curation of massive, high-quality pre-training data. It proved that a general-purpose language encoder can achieve superhuman performance on specialized benchmarks by leveraging the latent knowledge acquired during large-scale self-supervised learning.
The Limits of Bidirectional Encoding
The success of BERT demonstrated that deep bidirectionality is a prerequisite for robust language understanding. The decision to prioritize joint context over next-token prediction revealed that the structural requirements for "understanding" are distinct from those for "generation." This principle remains the central theme of encoder-focused research, influencing the development of models such as RoBERTa and ELECTRA. It leaves open the question of whether the computational overhead of bidirectional processing can be reconciled with the efficiency of autoregressive generation, or if the two tasks necessitate fundamentally different architectural primitives.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
BERT: Bidirectional Transformers (Official arXiv)
arXiv • article
Explore ResourceThe Illustrated BERT (Jay Alammar)
Blog • article
Explore ResourceBERT: State of the Art NLP (Hugging Face)
Hugging Face • article
Explore ResourceBERT Research Paper Walkthrough (Video)
YouTube • video
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.