DALL-E 2 and the Future of Imagination
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., & Chen, M. (2022). Hierarchical text-conditional image generation with CLIP latents. arXiv preprint arXiv:2204.06125.
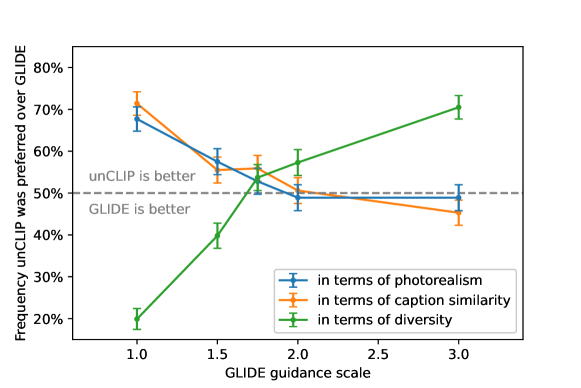
The 2022 DALL-E 2 paper from OpenAI introduced a hierarchical approach to generating images from natural language. While earlier models directly mapped text tokens to pixel values, DALL-E 2 employs a two-stage process that first maps text to a CLIP image embedding and then decodes that embedding into a final image. This architecture separates conceptual intent from graphical execution, allowing for greater control over image variations and style without changing the underlying meaning of the prompt.
The first stage of the system uses a diffusion prior to generate a continuous CLIP image embedding from text input. Researchers found that a diffusion-based prior is more computationally efficient and produces higher-quality results than autoregressive alternatives. This suggests that diffusion processes are better suited for mapping between semantic spaces than discrete token prediction. The prior serves as the conceptual engine of the system, defining the core visual ideas before they are rendered into a specific image.
The second stage is a 3.5 billion parameter diffusion decoder based on the GLIDE architecture. This decoder inverts the predicted CLIP embedding to produce the final image, utilizing a hierarchical chain of diffusion upsamplers to reach a resolution of 1024 by 1024. By using classifier-free guidance, the model can achieve high photorealism while maintaining the semantic diversity of the latent space. This process demonstrates that generating high-resolution visual data is most effective when the low-frequency conceptual structure is established before high-frequency details are added.
The hierarchical structure allows for the manipulation of images through their high-level latent representations. By keeping a CLIP embedding fixed and varying the noise in the diffusion decoder, the model can generate semantic variations of an input image that maintain its core identity. This indicates that generative systems can be used to explore different visual interpretations of a single idea. The ability to traverse these latent spaces marks a significant development in the precision of image synthesis and editing.
A known limitation of this approach is the compositional bottleneck caused by CLIP's compression of images into a single vector. This can lead to failures in correctly binding specific attributes to objects in a scene, as precise spatial relationships may be lost during the encoding process. This highlights a challenge in high-level semantic representation where efficiency comes at the cost of detail. Future developments may require architectural adjustments that better preserve spatial geometry while maintaining conceptual flexibility.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
OpenAI DALL-E 2 Blog
OpenAI • article
Explore ResourceDALL-E 2 Explanation
Towards Data Science • article
Explore ResourceDALL-E 2 Paper on arXiv
arXiv • article
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.