The Math Behind High-Speed AI Art
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 10684-10695).

In 2021, researchers at LMU Munich and Runway introduced Latent Diffusion Models (LDM), later commercialized as Stable Diffusion, to address the computational overhead of high-resolution image synthesis. While previous diffusion models operated directly on image pixels, they were restricted by significant memory and compute requirements. The researchers demonstrated that by performing the diffusion process within a compressed latent space - a lower-dimensional mathematical representation of an image - high-fidelity generation can be achieved on consumer-grade hardware. This architectural shift decoupled the semantic creation of content from the high-resolution rendering of pixels.
Diffusion in Latent Space and VAE Compression
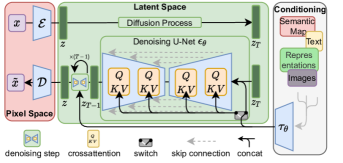
The core technical mechanism of the framework is the use of a pre-trained Variational Autoencoder (VAE) to map images into a latent manifold. This encoder compresses the input by a factor of 8 or more, capturing essential semantic features while discarding perceptually irrelevant high-frequency noise. The diffusion process - consisting of iterative denoising via a U-Net architecture - occurs entirely within this reduced space. This methodological choice established that the efficiency of generative models is determined by the dimensionality of the representation they manipulate. By optimizing the manifold rather than the raw pixel grid, the model achieves a significant reduction in training and inference complexity without sacrificing visual quality.
Classifier-Free Guidance and Semantic Steering
A critical component for the steerability of Stable Diffusion is Classifier-Free Guidance (CFG). During the training phase, the model is exposed to both captioned images and a fraction of "unconditional" samples where the text prompt is null. At inference time, the system computes two denoising trajectories: one conditioned on the user's prompt and one unconditional. By extrapolating the difference between these paths - modulated by a CFG scale - the model amplifies the features corresponding to the prompt. This finding proved that user instructions act as directional vectors in the latent space, and increasing the guidance scale forces the model toward a more precise, though potentially less diverse, interpretation of the input text.
Universal Conditioning via Cross-Attention
The LDM architecture utilizes a cross-attention mechanism to integrate diverse conditioning signals into the generative process. This mechanism allows the latent U-Net to "attend" to external information - such as BERT-based text embeddings, depth maps, or semantic layouts - during every stage of the denoising process. This finding transformed diffusion models from simple stochastic generators into universal synthesis engines that can follow complex, multi-modal instructions. It established that the most robust way to guide generation is to provide the model with an explicit interface for mapping external concepts to the internal latent representation.
Structural Control and Pixel-Level Constraints
The versatility of the latent representation enabled subsequent developments in spatial steering, most notably ControlNet. This auxiliary network provides a method for enforcing rigid structural constraints - such as edge maps, human poses, or surface normals - on the generation process without retraining the base diffusion model. By training a copy of the U-Net’s encoding layers and adding their output to the original skip connections, ControlNet allows for pixel-perfect composition. This engineering shift proved that the latent space possesses sufficient semantic depth to accommodate fine-grained spatial instructions while maintaining the high-level coherence of the generated scene.
Efficiency and the Democratization of Synthesis
The success of Stable Diffusion demonstrated that the progress of generative AI is driven as much by algorithmic efficiency as it is by data scale. By proving that high-performance models can operate within the memory constraints of standard GPUs, the research enabled a wave of open-source innovation and community-driven development. This realization remains the central theme of current research into real-time synthesis, including Latent Consistency Models (LCM) and Turbo models, which reduce the number of required denoising steps. It leaves open the question of whether there exists a fundamental mathematical limit to latent compression or if the next leap in synthesis will require a move beyond fixed-grid latent representations toward truly continuous manifolds.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
High-Resolution Image Synthesis (Official arXiv)
arXiv • article
Explore ResourceStable Diffusion Announcement (Stability AI)
Stability AI • article
Explore ResourceGitHub: Latent Diffusion Reference
GitHub • code
Explore ResourceA Visual Guide to Diffusion (Blog)
Jay Alammar • article
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.