The Moment Language Models Became Superhuman
Brown, T. B., et al. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
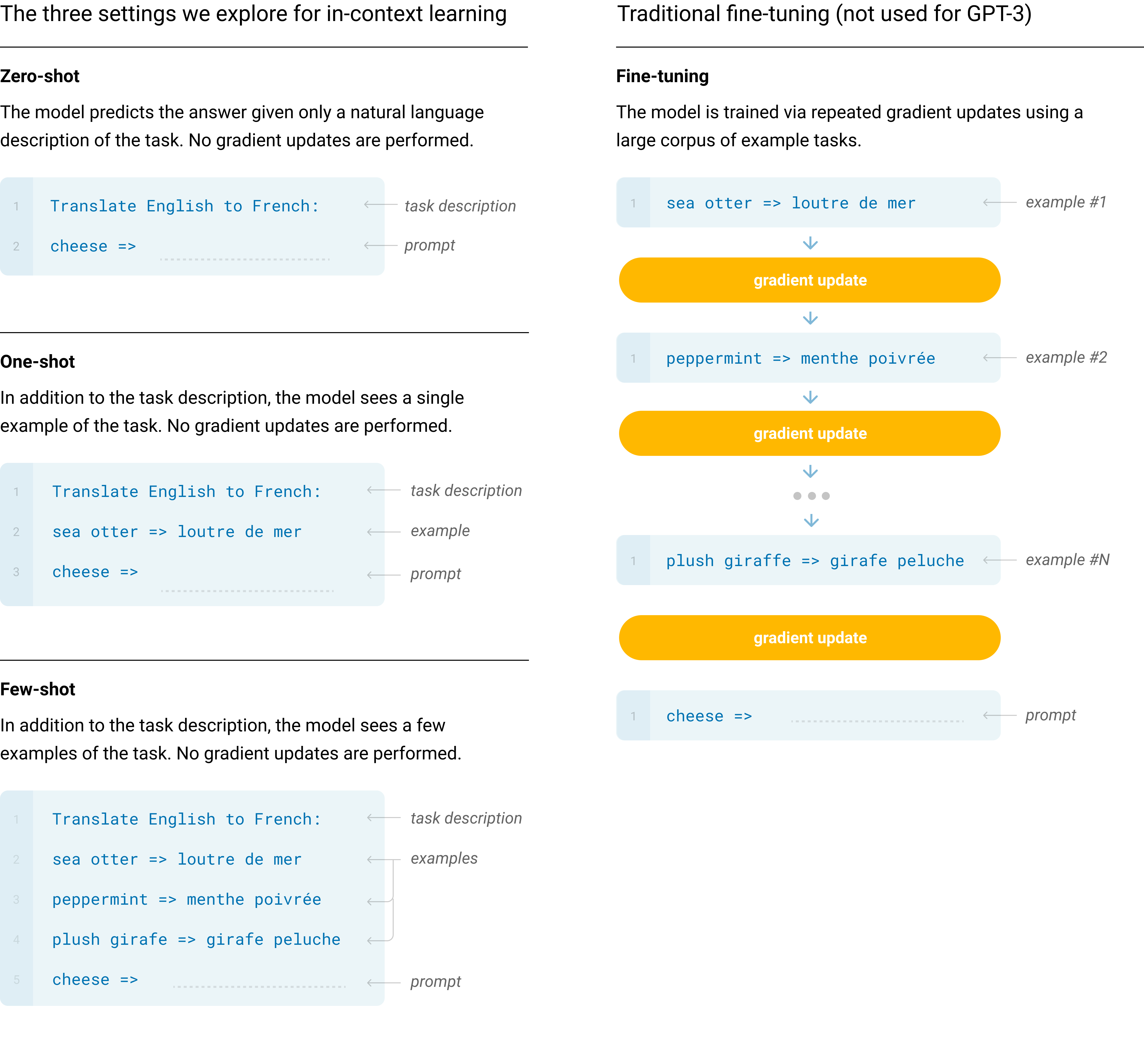
The 2020 release of GPT-3 represented a move away from the traditional pre-train and fine-tune workflow in artificial intelligence. As model complexity increased, the need for thousands of labeled examples for every task became a significant bottleneck. Researchers at OpenAI proposed that massive models could perform tasks by observing only a few examples in their input context. This few-shot learning capability suggests that large-scale language models can identify patterns and logic in real time through in-context learning rather than through explicit task-specific weight updates.
At a scale of 175 billion parameters, the model demonstrates meta-learning abilities, treating task descriptions and examples as part of its sequential environment. This allows the model to identify underlying rules and apply them without needing to update its internal weights for every new application. This transition effectively turned the language model into a general-purpose engine that can be reconfigured through natural language prompts. This shift has significant implications for the scalability and accessibility of artificial intelligence systems.
The architecture of GPT-3 consists of 96 transformer decoder layers, each with 96 attention heads and a hidden dimension of 12,288. To manage the computational and memory requirements of 175 billion parameters, the researchers used alternating dense and locally banded sparse attention patterns. This design allows the model to maintain coherence over a 2048-token context window while mitigating the quadratic memory overhead associated with standard attention. These engineering choices were necessary to support the unprecedented scale of the system.
The model was trained on a 300-billion token corpus designed to represent a broad range of human thought. This data included a filtered version of Common Crawl, high-quality book collections, and the entirety of English Wikipedia. By prioritizing high-quality, long-form human reasoning during training, the researchers ensured that the model developed deep latent associations. This extensive exposure allowed GPT-3 to achieve zero-shot performance across many domains without being explicitly instructed in those specific areas.
Evaluation across zero-shot, one-shot, and few-shot paradigms revealed a steep scaling law for few-shot performance. In many tasks, the 175-billion parameter model in few-shot mode matched or exceeded the performance of models specifically fine-tuned on thousands of examples. This demonstrates that large models are highly effective at using provided context to resolve ambiguity and align with user intent. However, the model still suffers from limitations such as factual hallucination and a recency bias that can prioritize the most recent examples over initial instructions.
The success of GPT-3 provided evidence for the scaling hypothesis, which posits that increases in compute, data, and parameters lead to qualitatively different forms of intelligence. It established a 175-billion parameter benchmark for frontier models and shifted the focus of research toward the emergence of generalist systems. The move toward in-context learning has influenced the development of the broader AI ecosystem, including the creation of agentic systems and the field of prompt engineering.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Language Models are Few-Shot Learners (Original Paper)
arXiv • article
Explore ResourceOpenAI: GPT-3 Research Blog
OpenAI • article
Explore ResourceA Visual Guide to How GPT-3 Works (Jay Alammar)
Blog • article
Explore ResourceGPT-3 Technical Overview
YouTube • video
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.