Fine-Tuning Huge AI Models on a Laptop
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., ... & Chen, W. (2021). Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
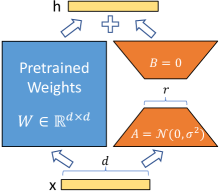
The 2021 LoRA paper by Hu et al. introduced a more efficient method for adapting large language models to specific tasks. Prior to this, fine-tuning large models required either full updates to hundreds of billions of parameters or the addition of extra layers that increased inference latency. Full fine-tuning was computationally expensive and difficult to store for multiple applications, while adapter layers slowed down processing. LoRA addresses these issues by reparameterizing weight updates as low-rank decompositions, allowing for task-specific adaptation without significant resource overhead.
The method involves freezing the pre-trained weight matrix and representing the change in weights as the product of two smaller matrices. These low-rank matrices capture task-specific information using only a tiny fraction of the total parameter count. This approach reduces memory requirements during training and allows the updated weights to be merged back into the original model for inference. This ensures that the adapted model maintains the original architecture and speed, proving that large systems can be steered effectively through targeted, low-dimensional updates.
The success of LoRA supports the low intrinsic dimension hypothesis, which suggests that weight changes during fine-tuning often occur within a very low-rank subspace. Researchers found that for models as large as GPT-3, a rank as low as one or two was frequently sufficient to match the performance of full fine-tuning. This indicates that large models are over-parameterized and that adaptation is primarily about amplifying existing patterns rather than creating new ones from scratch. Intelligence in these systems can thus be directed through the manipulation of a small portion of their total capacity.
A significant advantage of this technique is the elimination of additional computational cost during inference. Because the low-rank updates can be pre-computed and merged directly into the base model's weights, there is no change to the model's structure. This allows for real-time deployment of specialized models without the latency introduced by traditional adapter modules. The efficiency of the method makes it highly scalable for production environments where many different task-specific versions of a model may be required.
While effective, LoRA's reliance on low-rank updates assumes that the target task aligns with the model's existing pre-trained knowledge space. Tasks requiring radical departures from a model's world model may still require more extensive weight updates or architectural changes. The precise boundary between tasks that can be handled through weight-space steering and those requiring full re-training remains a subject of ongoing study. The method has become a standard tool in the efficient deployment of large-scale AI systems.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
LoRA Paper (arXiv)
arXiv • article
Explore ResourceFine-tuning with LoRA (Blog)
Hugging Face • article
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.