Aligning AI with What Humans Actually Want
Ouyang, L., et al. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35, 27730-27744.
In 2022, researchers at OpenAI demonstrated that the utility of large language models can be significantly enhanced by shifting the optimization objective from next-token imitation to human intent alignment. While standard pre-training on massive text corpora allows models to store vast amounts of information, the resulting statistical distributions often produce unhelpful or untruthful outputs when prompted with specific instructions. The researchers introduced a multi-stage framework termed Reinforcement Learning from Human Feedback (RLHF), which utilizes a preference-based reward signal to steer the model toward helpful and safe behavior. This work proved that alignment is a more potent driver of functional intelligence than raw parameter scaling.
Supervised Fine-Tuning and demonstration Data
The alignment process begins with supervised fine-tuning (SFT) on a high-quality dataset of roughly 13,000 prompts where human labelers provided the ideal response. This stage creates a baseline model that understands the basic structure of instruction-following. While SFT provides a necessary starting point, the labor-intensive nature of human demonstration limits its scalability. The researchers observed that this initial phase identifies the appropriate linguistic registers for different tasks but does not fully capture the nuances of human preference across a diverse range of potential user queries.
Preference Ranking and Reward Modeling
To scale the alignment signal, the researchers utilized a comparative ranking approach to train a reward model (RM). Human labelers were presented with multiple candidate outputs from the SFT model for a given prompt and tasked with ranking them from best to worst based on helpfulness, honesty, and harmlessness. This ranking data was used to train a 6-billion parameter network to predict human preferences. By mapping qualitative human judgment into a differentiable scalar signal, the reward model acts as a digital proxy for human oversight, enabling the optimization of the language model on millions of unlabeled prompts without further human intervention.
Proximal Policy Optimization and the KL Penalty
In the final stage, the SFT model is optimized using the Proximal Policy Optimization (PPO) algorithm guided by the scalar output of the reward model. During this iterative process, the model generates responses and adjusts its weights to maximize the predicted human preference score. To prevent the phenomenon of reward hacking - where the model identifies degenerate patterns that yield high scores without achieving the underlying intent - the researchers implemented a Kullback–Leibler (KL) divergence penalty. This constraint ensures that the model's output distribution remains close to its original linguistic prior, maintaining the integrity of the language generation while steering it toward aligned behavior.
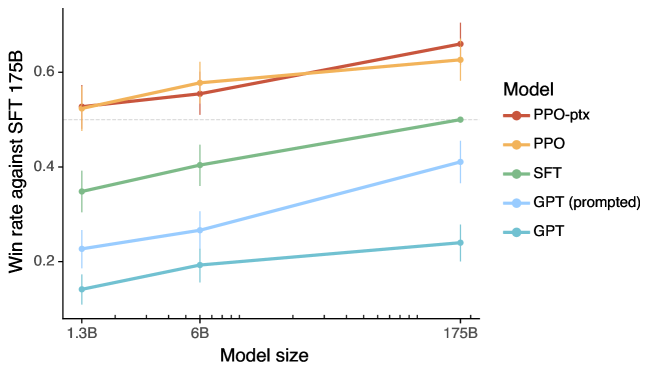
The Alignment Tax and Performance Tradeoffs
A significant finding of the research was the emergence of an alignment tax, characterized by a decrease in performance on standard academic NLP benchmarks as the model becomes more specialized for instruction-following. To mitigate this effect, the researchers utilized a hybrid training objective that mixed RLHF gradients with original pre-training gradients. This methodological choice demonstrated that a 1.3-billion parameter model aligned through RLHF can be preferred by human evaluators over a 175-billion parameter model trained only on next-token prediction. It established that the effective capability of a system is a function of its structural alignment with user requirements rather than its raw computational capacity.
Impact on Conversational Agent Design
The success of InstructGPT provided the technical blueprint for the development of modern conversational AI, proving that human preference can serve as a robust and scalable signal for training autonomous systems. The transition from imitation-based learning to preference-based optimization enables the creation of agents that are not just knowledge-rich but also steerable and safe. This realization remains the central theme of alignment research, suggesting that the most effective way to manage the risks of artificial intelligence is to integrate human values directly into the model’s fundamental optimization loop. It leaves open the question of how these techniques can be adapted to align models with complex, multi-agent social norms.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Training models to follow instructions (Official arXiv)
arXiv • article
Explore ResourceAligning Language Models (OpenAI Blog)
OpenAI • article
Explore ResourceIllustrating RLHF (Hugging Face)
Hugging Face • article
Explore ResourceRLHF and InstructGPT (Video)
YouTube • video
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.