The Hardware Trick That Sped Up Transformers
Dao, T., Fu, D. Y., Ermon, S., Rudra, A., & Ré, C. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. arXiv:2205.14135.
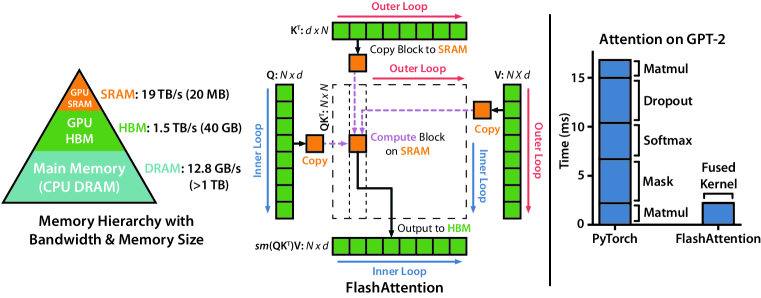
The 2022 FlashAttention paper introduced a significant optimization that allowed transformers to process much longer sequences by addressing memory bottlenecks. Historically, transformer context windows were limited by quadratic memory requirements, where doubling the sequence length quadrupled the memory needed. Researchers at Stanford University shifted the focus from reducing mathematical operations to optimizing data movement within the GPU. This transition from compute-bound to memory-bound optimization proves that the primary bottleneck in modern AI is often data movement rather than raw calculation speed.
FlashAttention achieves efficiency by being IO-aware, explicitly managing data flow between a GPU's fast internal SRAM and its slower high-bandwidth memory. Instead of storing the entire attention matrix, the algorithm uses tiling to break the query, key, and value matrices into smaller blocks that fit within fast internal memory. By storing only the statistics needed to recompute results on-the-fly, FlashAttention reduces memory complexity from quadratic to linear. This approach demonstrates that algorithms can be made faster by increasing mathematical work if that work minimizes expensive data transfers.
The use of tiling allows the attention mechanism to be computed in blocks, keeping data local and reducing the distance it must travel. During the learning phase, intermediate calculations are recomputed rather than stored, further reducing the memory footprint. This finding suggests that the memory wall in AI can be bypassed by treating data as a temporary signal for processing rather than an object for long-term storage. Effective system design thus requires a deep understanding of the physical constraints of the hardware on which the software runs.
In practical tests, FlashAttention enabled context windows of up to 128,000 tokens on standard hardware, representing a significant increase in capacity. This led to a 7.6-fold speedup in attention calculations, allowing models to process long documents or entire books in a single pass. This proved that transformer architectures are more capable than previous implementations had indicated. It also suggests that future progress in AI performance may depend as much on efficient information flow as on increased chip power.
The success of FlashAttention indicates that the true limits of AI memory are often defined by software's awareness of hardware architecture. By optimizing for the specific way GPUs handle memory, researchers have expanded the boundaries of what large-scale models can process. This methodology has become essential for training the current generation of long-context models. The continued development of hardware-aware algorithms is likely to remain a critical area of focus in the scaling of artificial intelligence.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
FlashAttention Paper on arXiv
arXiv • article
Explore ResourceGitHub Implementation
GitHub • code
Explore ResourceTri Dao's Blog Post
Tri Dao • article
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.