The Explosion of Open-Source AI
Touvron, H., Lavril, T., Izacard, G., Martinet, X., et al. (2023). LLaMA: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
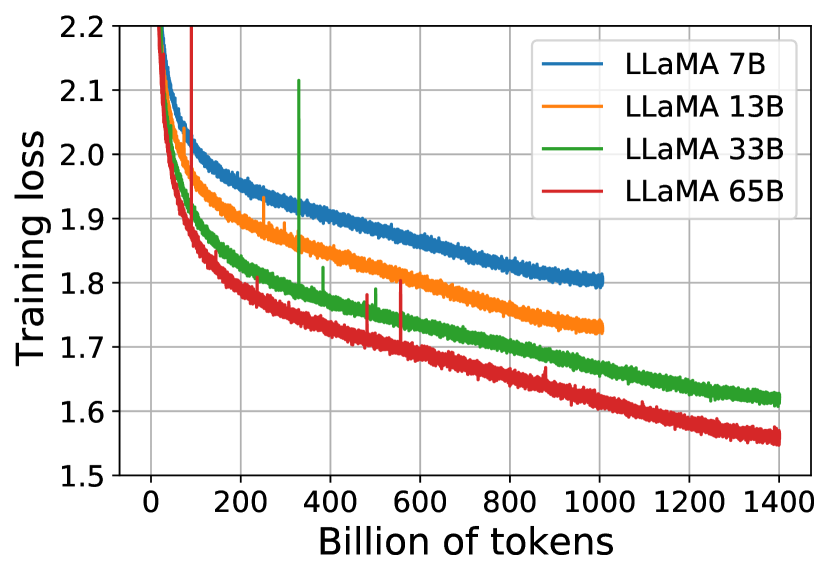
The 2023 LLaMA paper from Meta AI challenged the assumption that increasing parameter counts is the only path to better AI performance. While models had reached 175 billion parameters, researchers focused on training smaller models, ranging from 7 to 65 billion parameters, on much larger datasets. They demonstrated that a 13-billion parameter model could outperform larger systems if trained on high-quality data for a longer duration. This represented a shift toward a data-centric view of model development that prioritizes efficiency and deployment feasibility.
LLaMA redefined foundation model scaling by emphasizing extended training on high-quality data over raw size. By training a 7-billion parameter model on 1.4 trillion tokens, the study showed that smaller architectures are often under-trained rather than limited by their size. The approach incorporated architectural refinements such as RMSNorm for stability, the SwiGLU activation function for expressive power, and rotary positional embeddings for better modeling of relative distances. This proved that maximizing performance-per-parameter creates compact models that are easier to deploy and maintain.
The performance of LLaMA was driven by a curated mixture of seven datasets, with English CommonCrawl and C4 providing the core linguistic knowledge. Researchers used line-level deduplication and fastText filtering to ensure a high-signal training corpus. This was supplemented by GitHub data for technical reasoning, ArXiv for scientific rigor, and Wikipedia for general knowledge. This specific data mixture suggests that model intelligence arises from a balance of broad linguistic fluency and specialized technical information.
Architectural modifications to the standard transformer design further improved the model's stability and performance. Replacing standard layer normalization with RMSNorm at the input of each sub-layer and using SwiGLU instead of ReLU in feed-forward layers provided significant stability and expressive gains. The use of rotary positional embeddings at every layer improved the model's ability to capture relationships between tokens regardless of their position. These choices synthesized best practices in neural network design into a robust and efficient architecture.
The release of LLaMA weights led to a significant increase in community-driven AI research and innovation. This availability highlighted a tension between open collaboration and the need for responsible deployment. The success of the model suggests that the value of foundation models lies not only in their weights but also in the ecosystem that develops around their use. The trend toward efficient, high-performance models continues to influence the direction of both academic research and commercial AI applications.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Meta AI LLaMA Blog
Meta AI • article
Explore ResourceLLaMA Paper on arXiv
arXiv • article
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.