How to Control an Intelligence Greater Than Ours
Burns, C., Izmailov, P., Kirchner, J. H., Bowyer, B., ... & Leike, J. (2023). Weak-to-strong generalization: Eliciting strong capabilities with weak supervision. arXiv preprint arXiv:2312.09390.
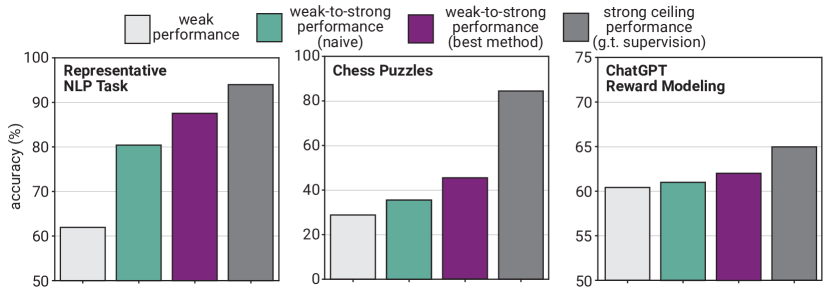
The 2023 paper on weak-to-strong generalization from OpenAI’s Superalignment team investigated the feasibility of using humans to align artificial intelligence systems that exceed human intelligence. Historically, alignment has relied on the assumption that a supervisor can accurately recognize and reward correct behavior in a student model. As AI capabilities surpass human expertise in specialized domains, this supervisor-student relationship becomes strained. The researchers introduced a framework to determine if a less capable model can effectively guide a more capable one to perform tasks that the supervisor itself cannot master.
The Weak-to-Strong Framework

The experimental setup involved a smaller model generating labels for a significantly larger and more capable model. The study aimed to identify whether the stronger model would merely replicate the supervisor's errors or if it could generalize from the weak feedback to uncover the true underlying logic of the task. Results indicated that a strong model can often outperform its teacher if the learning objective encourages internal consistency rather than pure imitation. This finding demonstrated that intelligence can be steered from a position of relative weakness, suggesting that alignment does not require the supervisor to be more intelligent than the system being governed.
Auxiliary Loss and Internal Priors
To mitigate the risk of the strong model inheriting the biases and mistakes of the weak supervisor, the researchers implemented an auxiliary loss function. This function encourages the student model to rely on its own latent representations and internal confidence levels. When the supervisor's labels conflict with the student's internal model of the task, the loss function reduces the penalty for deviating from the provided instruction. This mechanism revealed that larger models possess an internal understanding of tasks that is frequently more accurate than the explicit guidance they receive during fine-tuning. By prioritizing internal coherence, the model can filter out the noise in the supervision signal and move toward a more accurate representation of the target goal.
The Generalization Gap
Despite the positive results, the study identified a persistent generalization gap where models trained by a weak supervisor underperform relative to those trained by a strong supervisor. This gap highlights a fundamental challenge in scaling alignment: as the disparity between the supervisor and the student increases, the feedback provided by the teacher becomes progressively more difficult for the student to resolve accurately. The existence of this gap proves that aligning superintelligent systems is not an automatic outcome of scaling but requires specific technical innovations in auxiliary objectives and architectural design. It leaves open the question of whether this gap can be bridged through iterative refinement or if new paradigms of recursive supervision will be required.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Weak-to-Strong Generalization (arXiv)
arXiv • article
Explore ResourceOpenAI Superalignment Blog
OpenAI • article
Explore ResourceGitHub: Weak-to-Strong
GitHub • code
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.