Training AI with a Digital Constitution
Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., ... & Kaplan, J. (2022). Constitutional AI: Harmlessness from AI Feedback. arXiv preprint arXiv:2212.08073.
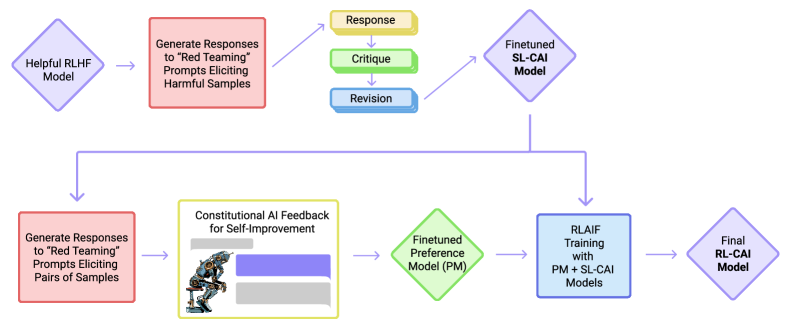
In 2022, researchers at Anthropic introduced a method for aligning large language models that utilizes a structured, rule-based approach to replace the human preference bottleneck. This process, termed Reinforcement Learning from AI Feedback (RLAIF), allows a model to autonomously supervise its behavior based on a fixed set of natural language principles known as a constitution. By moving away from the expensive and inconsistent evaluations provided by human rankers, Constitutional AI provides a scalable framework for ensuring model harmlessness while maintaining transparency in the alignment process.
The Self-Critique and Revision Loop
The alignment process begins with a self-supervised loop where the model revises its own responses to comply with constitutional standards. When prompted to generate potentially harmful or unhelpful content, the model produces an initial draft followed by a natural language critique based on a specific principle from the constitution. A final, revised output is then generated that incorporates the feedback from the critique. This mechanism demonstrated that a model with sufficient reasoning capability can identify and correct its own deviations if provided with a consistent logical framework. It suggested that the latent knowledge required for safe behavior is already present in pre-trained weights and can be activated through precise instructions.
Reinforcement Learning from AI Feedback
Following the initial revision phase, the model generates preference labels for a large dataset by comparing pairs of potential responses and selecting the one that best adheres to the constitution. This step replaces the traditional requirement for human-labeled data in training a reward model. The resulting automated preferences guide a reinforcement learning process, typically using Proximal Policy Optimization (PPO), to refine the model's final policy. This shift revealed that alignment can scale at the same rate as pre-training compute, as the source of truth is shifted from human rankers to an inspectable and permanent set of written rules. It proved that the most effective way to align a machine is to provide it with the logical tools necessary to evaluate its own reasoning against a defined standard.
Transparency and Scaling Safety
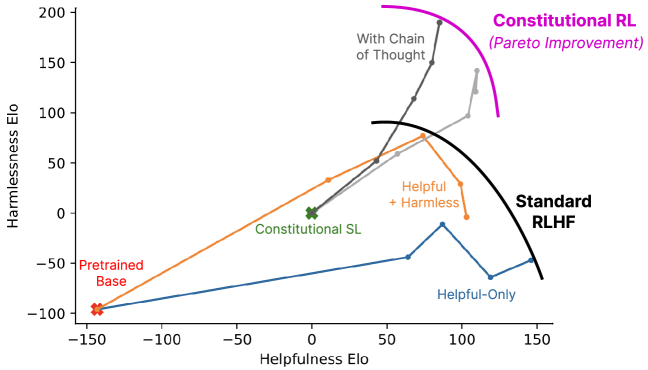
Constitutional AI demonstrated that a transparent set of rules provides a more robust alignment signal than the opaque and subjective preferences of crowdsourced human evaluators. Because the constitution is defined in natural language, it serves as a controllable interface that can be audited, debated, and updated by human designers without requiring a new round of data collection. In testing, models trained via RLAIF often outperformed those trained with standard human-driven reinforcement learning on complex reasoning tasks, suggesting that a structured rule set can enhance rather than degrade model utility. This approach highlights the potential for defining algorithmic laws that are simple enough for human understanding but precise enough to govern autonomous systems.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Constitutional AI (arXiv)
arXiv • article
Explore ResourceAnthropic Constitutional AI Blog
Anthropic • article
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.