Why Transformers Are Replacing Traditional Vision
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., ... & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
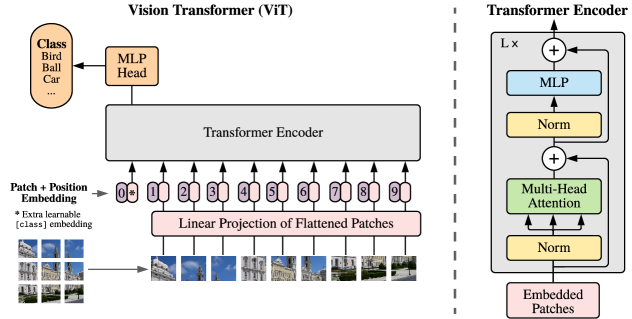
In 2020, researchers at Google Research demonstrated that the Transformer architecture, originally designed for natural language processing, can outperform convolutional neural networks (CNNs) on large-scale image recognition tasks. Prior to this research, computer vision was dominated by architectures that utilized hand-coded inductive biases, such as translation invariance and locality, to process pixel data. The researchers proved that by treating an image as a sequence of discrete patches and removing these built-in assumptions, a general-purpose attentive model can learn the spatial relationships of the physical world directly from data, establishing a unified framework for both vision and language.
Spatial Discretization and Patch Embeddings
The core technical mechanism of the Vision Transformer (ViT) is the spatial discretization of the input image into fixed-size patches. An image of resolution is reshaped into a sequence of flattened 2D patches, each of which is then linearly projected into a high-dimensional embedding space. This methodological choice allows the model to process visual information as a 1D sequence of tokens, identical to the way words are represented in a language model. This finding revealed that the specific grid geometry of an image is not a necessary architectural prior, but a structural pattern that can be efficiently managed through global self-attention rather than local convolution.
Global Self-Attention and Receptive Fields
The ViT architecture utilizes global self-attention from the very first layer, allowing every patch to interact with every other patch across the entire image simultaneously. In a standard CNN, the receptive field of a neuron is initially restricted to a small local neighborhood, and a global understanding only emerges through the hierarchical stacking of multiple layers. By enabling global information flow from the onset, ViT can capture long-range dependencies and complex relational structures - such as the alignment of distant features - without waiting for successive rounds of spatial pooling. This finding demonstrated that the most effective way to understand a complex visual scene is to ensure that the relational significance of every part is computed in parallel across the entire manifold.
Scaling Laws and the Inductive Bias Trade-off
A critical finding of the research is the relationship between model performance and the volume of training data. While CNNs are more efficient when data is limited due to their built-in spatial assumptions, the researchers proved that ViT scales more aggressively as the dataset size increases. When pre-trained on massive datasets such as ImageNet-21k (14 million images) or JFT-300M, the Vision Transformer consistently outperformed state-of-the-art ResNet architectures. This result established the principle that "intelligence" in vision is an emergent property of large-scale data ingestion, where a model with fewer architectural constraints eventually surpasses more specialized designs by discovering its own optimal processing rules.
Position Embeddings and Spatial Order
Because the Transformer contains no inherent knowledge of 2D geometry, ViT utilizes learnable position embeddings added to the patch representations to preserve spatial information. The model learns to identify which patches are adjacent and which are distant by observing the statistical regularities of the training set. The researchers observed that the learned position embeddings often exhibit clear 2D structures, with proximal patches having similar embedding vectors. This finding confirmed that the model autonomously reconstructs the concepts of distance and orientation, effectively digitalizing the Act of spatial perception through the refinement of a high-dimensional state space.
The Convergence of Vision and Language Architectures
The success of the Vision Transformer demonstrated that the fundamental primitives for processing information are increasingly independent of the data's original modality. The decision to use an identical encoder for both pixels and words revealed that the bottleneck in AI was the proliferation of specialized, non-interoperable designs. This principle remains the central theme in the development of multi-modal foundation models, where a single attentive block serves as the universal engine for all cognitive tasks. It leaves open the question of whether the computational cost of global self-attention - which scales quadratically with sequence length - can be reduced to support the processing of extremely high-resolution visual data.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
An Image is Worth 16x16 Words (Official arXiv)
arXiv • article
Explore ResourceTransformers for Image Recognition (Google AI Blog)
Google • article
Explore ResourceViT Reference Implementation (GitHub)
GitHub • code
Explore ResourceViT Walkthrough and Explanation (Video)
Yannic Kilcher • video
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.