Teaching Computers to See in Real-Time
Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 779-788).
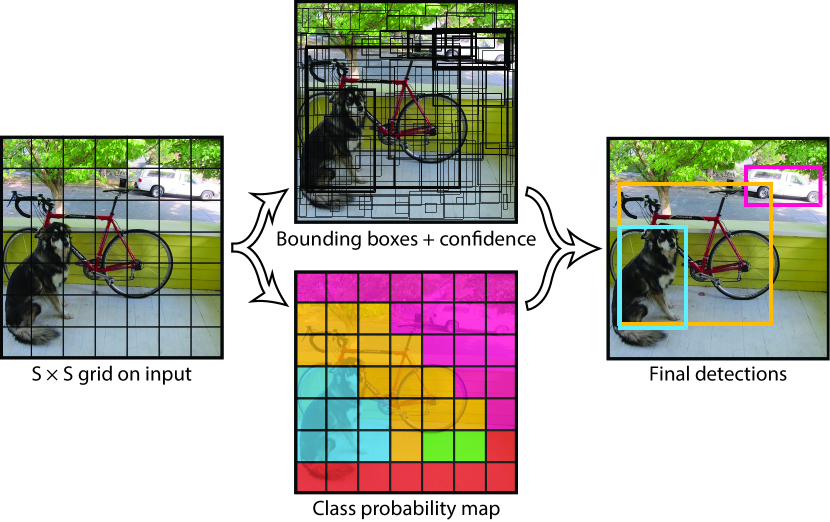
In 2015, Joseph Redmon and colleagues introduced YOLO (You Only Look Once), a framework that reframes object detection as a single regression problem mapping image pixels directly to bounding box coordinates and class probabilities. Prior to this research, object detection systems utilized multi-stage pipelines - such as R-CNN - that relied on region proposal algorithms followed by independent classification and refinement steps. The researchers demonstrated that by processing the entire image through a single convolutional network in a single forward pass, detection can be performed in real-time with high frames-per-second (FPS) throughput, enabling the transition of computer vision from static analysis to live video understanding.
Spatial Discretization and the Grid System
The core technical innovation of YOLO is the spatial discretization of the input image into an grid. For each grid cell, the model predicts a fixed number of bounding boxes and their corresponding confidence scores. If the center of an object falls within a specific cell, that cell is responsible for its detection. Unlike region-based methods that evaluate thousands of potential patches, YOLO utilizes a global receptive field, allowing the network to incorporate contextual information from the entire image. This finding proved that many false positive detections - where background patches are mistaken for objects - can be eliminated by providing the model with a holistic view of the scene during the inference phase.
Bounding Box Regression and Confidence Scoring
For each predicted bounding box, the model outputs five parameters: the center coordinates , the width and height , and a confidence score . The confidence score is defined as , where IOU represents the Intersection Over Union between the predicted box and the ground truth. Simultaneously, each grid cell predicts conditional class probabilities. During inference, these probabilities are multiplied by the individual box confidence scores to produce class-specific confidence values. This methodological choice established a unified representation for localization and classification, allowing for the efficient filtering of low-signal predictions without the need for redundant post-processing.
Multi-Part Loss Function and Optimization
Training the unified model requires a composite loss function that balances localization accuracy with classification precision. YOLO utilizes a sum-squared error objective divided into three functional components: localization loss, which penalizes errors in box coordinates and dimensions; confidence loss, which manages the distinction between empty cells and those containing objects; and classification loss, which targets incorrect category predictions. To address the fact that most cells in a typical image are empty, the researchers downweighted the loss for "no-object" cells () while increasing the weight for coordinate errors (). This finding revealed that the performance of a unified detector is determined by the strategic weighting of diverse optimization signals.
Real-Time Performance and Architectural Design
The YOLO architecture consists of 24 convolutional layers followed by two fully connected layers, a design inspired by the GoogLeNet model for image classification. By streamlining the detection pipeline into a single network, the "Fast YOLO" variant achieved a processing speed of 155 frames per second, while the standard model maintained 45 FPS on contemporary hardware. This achievement demonstrated that the computational cost of object detection can be reduced to a level suitable for autonomous systems and real-time surveillance. It proved that the efficiency of a single, integrated path through a neural network is often superior to the complexity of a fragmented, multi-stage pipeline.
Limitations of Spatial Constraints and Resolution
While YOLO provides high-speed global detection, its reliance on a fixed grid imposes specific technical constraints. Because each grid cell can only predict a limited number of bounding boxes and only one class, the model struggles to detect small objects that appear in dense clusters, a phenomenon known as the "flock" problem. Additionally, the use of sum-squared error treats errors in large and small boxes with equivalent weight, which can lead to localization inaccuracies for small objects where minor pixel shifts represent large relative errors. These findings suggested that the next leap in detection efficiency requires move toward multi-scale feature maps and more granular spatial representations.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
You Only Look Once (Official arXiv)
arXiv • article
Explore ResourceYOLO Project Page (Darknet)
Darknet • docs
Explore ResourceObject Detection Overview (Google Research)
Google • article
Explore ResourceYOLOv1 Research Paper Walkthrough (Video)
YouTube • video
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.