The AI That Understands Images Like a Human
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021). Learning transferable visual models from natural language supervision. In International conference on machine learning (pp. 8748-8763). PMLR.
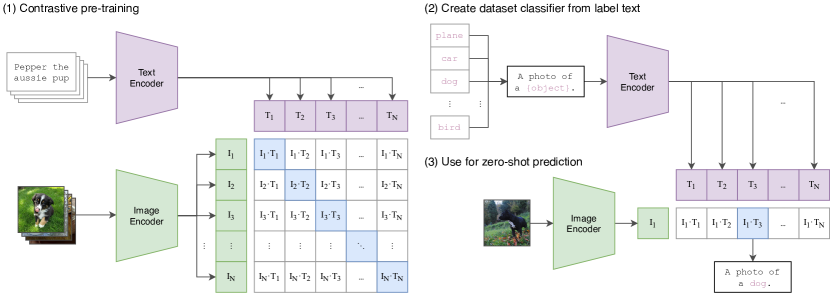
In 2021, researchers at OpenAI demonstrated that visual models can be effectively trained using natural language as a direct supervisory signal, replacing the requirement for fixed category labels. Prior to this work, computer vision models were restricted to discrete sets of labels - such as those in the 1,000-class ImageNet dataset - which limited their ability to generalize to novel concepts or diverse linguistic contexts. The researchers proved that by training separate vision and text encoders to maximize the similarity of correct image-caption pairs, a system can learn a shared semantic manifold where visual features are aligned with open-ended human concepts, establishing a foundation for zero-shot generalization across thousands of tasks.
Contrastive Pre-training and the Multi-modal Manifold
The primary technical contribution of the CLIP framework is the contrastive pre-training objective. For a batch of image-text pairs, the model is trained to maximize the cosine similarity of the correct pairings while minimizing the similarity of the incorrect pairings. This methodological choice forces the vision and text encoders to map their respective inputs into a unified high-dimensional embedding space. Within this shared manifold, a vector representing the word "dog" is geometrically proximal to all images containing dogs, regardless of their specific appearance or lighting. This finding established that the "meaning" of an image is a relational property that can be captured through its statistical alignment with the vast, unstructured context of human language.
Zero-Shot Transfer and Prompt Engineering
A critical achievement of CLIP is its ability to perform classification tasks without having been explicitly trained on the target labels. To evaluate the model on a new dataset, the names of the classes are converted into natural language descriptions, such as "a photo of a {label}," and passed through the text encoder. The image is then classified into the category whose text embedding has the highest cosine similarity with the image embedding. This discovery revealed that a model's utility is determined by the breadth of the conceptual space it has encountered during training rather than the specificity of its output layer. It established natural language as the most flexible interface for steering artificial intelligence, effectively digitalizing the Act of zero-shot task specification.
Distributional Robustness and Contextual Invariance
The researchers observed that models trained via natural language supervision exhibit significantly higher robustness to distribution shift compared to standard supervised models. While a model trained on ImageNet often fails when presented with sketches, cartoons, or distorted photos, CLIP maintains high accuracy across these diverse visual styles. This resilience suggested that by learning from the rich context of human speech, the model captures the invariant "essence" of concepts rather than the narrow pixel correlations of a specific dataset. This finding established that the bottleneck in visual reliability was the rigidity of traditional labeling schemes, and that language-based alignment provides a more generalized understanding of physical reality.
Multi-Modal Foundations for Generative AI
The practical significance of CLIP is most evident in its role as the foundational alignment engine for generative models like DALL-E and Stable Diffusion. By providing a method for measuring the semantic distance between text and pixels, CLIP enabled the development of systems that can synthesize images based on complex, open-ended prompts. This application proved that the scalability of artificial intelligence is determined by the adoption of architectures that treat different information modalities as facets of a single underlying logical structure. The work transformed computer vision from an isolated discipline into a component of a larger multi-modal reasoning framework.
The Logic of Semantic Coherence
The success of CLIP demonstrated that the complexity of the visual world can be accurately represented through its relationship to symbolic human knowledge. The decision to prioritize contrastive alignment over direct classification revealed that the primary constraint on artificial vision was the structural isolation of visual features from their linguistic descriptions. This principle remains the central theme in modern foundation model research, influencing the development of large-scale multi-modal encoders and the study of cross-modal retrieval. It leaves open the question of whether there exist visual concepts that are fundamentally inexpressible in language, and how these "silent" features can be integrated into a unified cognitive model.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Learning Transferable Visual Models (Official arXiv)
arXiv • article
Explore ResourceCLIP: Connecting Text and Images (OpenAI Blog)
OpenAI • article
Explore ResourceCLIP Reference Implementation (GitHub)
GitHub • code
Explore ResourceCLIP Explained (Hugging Face Blog)
Hugging Face • article
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.