Unlocking 3D Vision from 2D Photos
Yang, L., Kang, B., Huang, Z., Xu, X., Feng, J., & Zhao, H. (2024). Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data. arXiv:2401.10891.
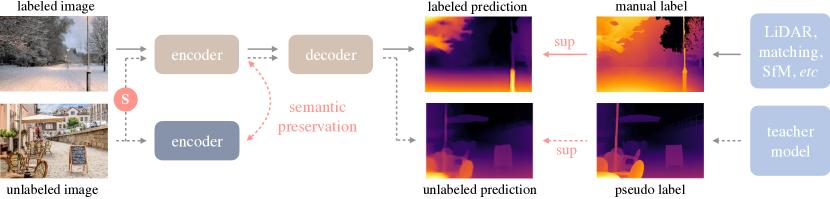
The 2024 paper 'Depth Anything' marked a fundamental shift in how machines perceive the three-dimensional structure of the world from a single two-dimensional image. Before this, Monocular Depth Estimation was limited by a reliance on expensive, sensor-labeled datasets - like those from LiDAR - which are difficult to scale across diverse environments. Researchers proposed a move away from this 'data bottleneck' by using 62 million unlabeled images and a new student-teacher learning pipeline. They created a foundation model for depth that generalizes to virtually any scene, proving that geometric understanding can be learned at a massive scale without the need for manual, high-fidelity labels.
The 62 Million Image Engine
Depth Anything bypassed the data bottleneck of monocular depth estimation by leveraging 62 million unlabeled images through a robust student-teacher learning pipeline. Instead of relying on expensive, sensor-labeled datasets, the researchers used a teacher model to generate pseudo-depth labels for diverse web imagery, which a student model was then tasked to reconstruct from heavily distorted versions of those same images. This use of noise and blur forced the student to look past surface-level textures and identify the underlying geometric structure of a scene, often surpassing the teacher's original performance. By aligning these depth features with semantic priors from pre-trained encoders, the model proved that the "unlabeled" web contains sufficient signals for universal spatial reasoning if the learning objective is designed to prioritize structural invariance over pixel-level imitation.
Semantic Anchors for Geometry

How Depth Anything achieves its high-level scene understanding is by anchoring its geometric reasoning in semantic knowledge. The researchers forced the depth model to align its internal features with those of a foundation model that already understood what objects were. This revealed that 'knowing' what an object is - for example, a car vs. a road - is deeply coupled with 'seeing' how far away it is. By using semantic features as an anchor, the model learned to maintain a more coherent global structure of the scene. This finding suggested that the most effective way to solve geometry is to anchor it in semantic understanding, proving that the boundary between a model that sees and a model that understands is rapidly disappearing.
Zero-Shot Spatial Mastery

The success of Depth Anything was most evident in its 'zero-shot' performance on datasets it had never encountered during training. It consistently outperformed previous state-of-the-art models, even those that had been explicitly trained on the evaluation data. This revealed that a model's ability to generalize is a direct function of the diversity of its exposure during the pre-training phase, rather than the precision of any single dataset. It proved that monocular depth estimation has reached a threshold where a single, universal model can handle the complexities of any environment with equal precision. This raises the question of whether we still need specialized sensors for depth, or if vision alone is sufficient to reconstruct the three-dimensional world with the same fidelity as a human observer.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Depth Anything Project
Depth Anything Team • website
Explore ResourceDepth Anything Paper on arXiv
arXiv • article
Explore ResourceGitHub Repository
GitHub • code
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.