Efficient Attention for Massive Models
DeepSeek-AI. (2024). DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. arXiv preprint arXiv:2405.04434.
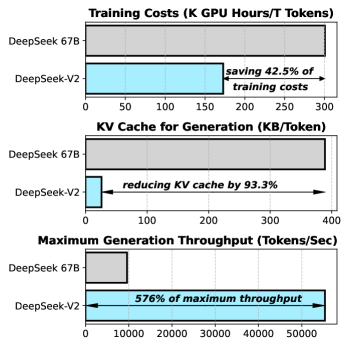
In 2024, DeepSeek-AI introduced DeepSeek-V2, a sparse Mixture-of-Experts (MoE) model characterized by extreme parameter efficiency and a significant reduction in KV cache memory requirements. The research addresses the primary scaling bottleneck of long-context language models: the linear growth of memory needed to store the keys and values for every token in a sequence. The researchers demonstrated that by implementing Multi-head Latent Attention (MLA), a system can achieve a 93% reduction in the cache footprint compared to standard architectures while maintaining full-rank expressive power, enabling high-concurrency inference on massive datasets without exceeding GPU memory limits.
Multi-head Latent Attention and Joint Compression
The technical core of MLA is the compression of individual key and value heads into a shared, low-rank latent vector. In a traditional Transformer, each attention head maintains its own high-dimensional vectors, which are cached for every token. MLA projects these vectors into a compressed latent space during the caching phase and only expands them back to their full rank during the actual attention calculation. This architectural adjustment proves that the informational content of the KV cache is significantly more redundant than previously assumed. To ensure that positional information does not interfere with this compression, the model utilizes a Decoupled Rotary Positional Embedding (RoPE) strategy, allowing it to compress the core informational signal without losing the structural context of the sequence.
Fine-grained MoE and Shared Experts
DeepSeek-V2 introduces a significant refinement to the Sparse MoE architecture by implementing a more granular division of labor. Traditional MoE systems use a few large experts, which can lead to routing instabilities and inefficient parameter usage. DeepSeek-V2 splits the experts into smaller, more numerous units - referred to as fine-grained experts - and designates a subset of "shared experts" that are active for every token. This dual-structure ensures that a common base of knowledge is always available, while the specialized experts provide the high-capacity reasoning required for complex tasks. The result is a massive increase in total parameters (236B) with a relatively small number of active parameters per token (21B), allowing the model to maintain a vast knowledge base at the speed and cost of a much smaller system.
Performance and Economic Scaling
The technical significance of DeepSeek-V2 is its demonstration that frontier-level performance can be achieved with significantly lower computational overhead. By optimizing the architecture for both training and inference, the researchers achieved a 42.5% reduction in training costs and a 5.6-fold increase in generation throughput compared to their previous dense models. This finding revealed that the most effective way to scale a network is to allow it to develop an increasingly intricate internal hierarchy, where the division of labor is balanced through a sophisticated load-balancing loss. It establish that the bottleneck of AI deployment is not merely the size of the model, but the efficiency with which its internal knowledge can be accessed and routed.
The Logic of Latent Representations
The success of DeepSeek-V2 established that the efficiency of an attention mechanism is a function of its informational density rather than its raw parameter count. The decision to manipulate compressed latent vectors revealed that the primary constraint on long-context intelligence was the reliance on uncompressed, high-rank representations of data. This principle remains the central theme in the search for next-generation architectures that can process millions of tokens natively. It leaves open the question of whether further expert fragmentation and latent-space optimization will eventually move toward a state where every individual parameter is dynamically routed based on the incoming signal.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
DeepSeek-V2 Paper (Official arXiv)
arXiv • article
Explore ResourceDeepSeek-V2 GitHub Repository
GitHub • code
Explore ResourceMixture-of-Experts Explained (Hugging Face)
Hugging Face • article
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.