The New Era of Open-Source Reasoning AI
DeepSeek-AI. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv preprint arXiv:2501.12948.
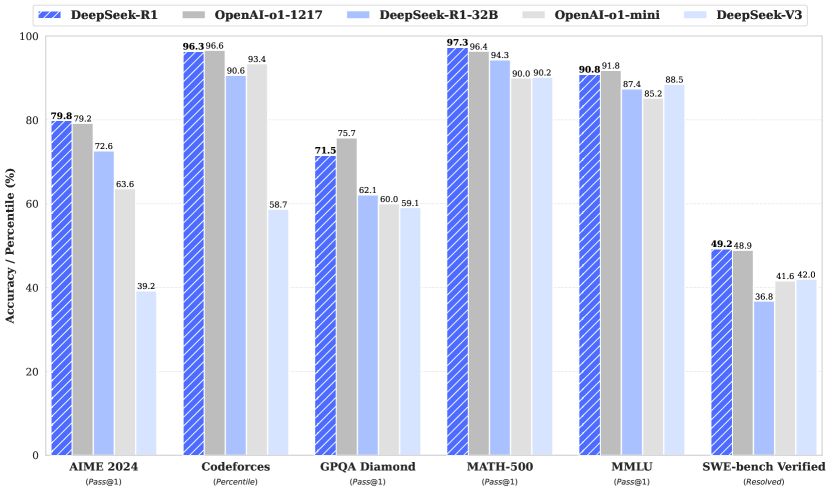
The 2025 DeepSeek-R1 paper marks a shift in the development of reasoning-oriented language models by moving away from a reliance on supervised fine-tuning. Previously, it was assumed that a model must first be shown how to reason through thousands of human-annotated examples before reinforcement learning could be effective. DeepSeek-R1 demonstrates that reasoning capabilities can instead be incentivized through reinforcement learning directly on a base model, allowing the system to discover its own logical strategies through objective feedback loops.
The development of DeepSeek-R1-Zero employed Group Relative Policy Optimization, an algorithm that calculates advantages relative to a group of sampled outputs. This approach reduced the computational overhead typically associated with maintenance of a separate critic model. The resulting reinforcement learning process allowed for the emergence of complex reasoning behaviors based purely on rule-based rewards for accuracy and formatting. The findings suggest that reasoning is a latent property of large-scale neural networks that can be unlocked through consistent feedback rather than simple imitation of human demonstrations.
Researchers observed the spontaneous emergence of self-correction behaviors during the training process. When faced with difficult problems, the model autonomously learned to pause, re-evaluate its initial logic, and pivot to more effective strategies. This behavior was not explicitly programmed but evolved as a means of maximizing rewards. This self-optimized allocation of thinking time suggests that deliberation in artificial systems can be an emergent property of the optimization landscape, allowing models to define their own internal pathways toward a solution.
The reasoning patterns discovered through massive reinforcement learning were successfully distilled into smaller, more efficient models. A 32-billion parameter model distilled from these reasoning samples outperformed similar models trained directly through reinforcement learning, indicating that the synthesized logic is a highly effective training signal. This distillation process proves that the complex reasoning found in large models can be compressed for use in smaller systems. However, these models still show a high sensitivity to prompt formatting and a tendency to default to specific languages in their internal monologue.
While progress in mathematical and logical domains has been significant, other areas such as software engineering still face challenges due to the high cost of asynchronous evaluations. The gap between abstract mathematical logic and practical interaction with complex systems remains a focus of ongoing research. The success of the DeepSeek-R1 framework highlights the potential for models to develop advanced cognitive skills through self-directed learning, but it also underscores the importance of refining the feedback mechanisms that guide these systems.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
DeepSeek R1 Paper (arXiv)
arXiv • article
Explore ResourceDeepSeek Official Blog
DeepSeek • article
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.