Inside the Most Powerful Model Ever Built
OpenAI. (2023). GPT-4 Technical Report. arXiv preprint arXiv:2303.08774.
The release of the GPT-4 Technical Report in 2023 marked a transition toward predictable engineering in the development of large language models. Before this, the performance of massive neural networks was often uncertain until training was complete. Researchers demonstrated that this unpredictability can be managed by training smaller versions of an architecture to map how mathematical loss follows a clear, measurable curve. This suggests that intelligence in these systems is a quantifiable trajectory that can be forecast before significant computational resources are committed to full-scale training.
A fundamental contribution of the GPT-4 project was the discovery that the behavior of large-scale systems can be predicted using prototypes as small as one ten-thousandth the final size. By using power law fits, the researchers could forecast final performance on tasks like coding and basic reasoning. This indicates that complex behaviors in large models are predictable outcomes of increased data and computation. The application of these scaling laws allows for the design of intelligent systems with a level of confidence comparable to traditional engineering disciplines.
GPT-4 was designed to natively accept both text and image inputs, processing visual data by breaking images into tokens that the central model reasons about. This enables the model to solve problems requiring a simultaneous understanding of visual and textual information, such as explaining a physics diagram. This finding suggests that the boundaries between different forms of data are largely artificial and that a sufficiently powerful model can learn a generalized representation of the world that transcends any single sensory modality.
The model's professional performance is supported by a post-training alignment process that uses automated classifiers as safety instructors. These rule-based reward models provide consistent signals to ensure the model refuses harmful requests while maintaining a helpful tone. This approach resulted in an 82% reduction in responses to disallowed content compared to previous versions. This demonstrates that safety and reliability are engineerable traits that can be systematically improved through targeted alignment strategies.
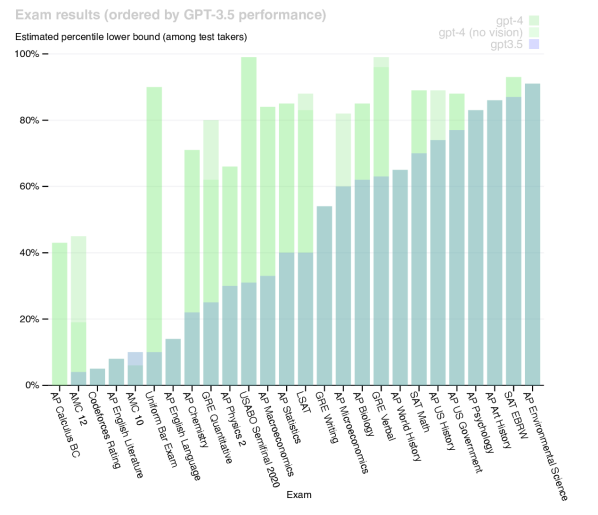
On professional and academic examinations, GPT-4 demonstrated a significant leap in performance, scoring in the 90th percentile on the Uniform Bar Exam. This suggests that reasoning capabilities have reached a threshold where models can handle tasks previously thought to require specialized human expertise. The success of the model on these benchmarks challenges existing definitions of cognitive labor and indicates that professional-grade reasoning can be scaled as a utility. How society and professional fields adapt to this capability remains an open question.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
GPT-4 Technical Report (arXiv)
arXiv • article
Explore ResourceOpenAI GPT-4 Blog
OpenAI • article
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.