Building an Open-Source Vision Assistant
Liu, H., Li, C., Wu, Q., & Lee, Y. J. (2023). Visual Instruction Tuning. arXiv:2304.08485.
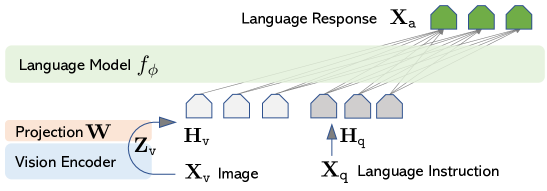
The 2023 emergence of LLaVA suggested that the most effective way to improve machine vision is through better language instruction rather than increasing the complexity of vision models. Prior multimodal systems were often trained for narrow tasks like classification, which limited their ability to engage in open-ended conversation. Researchers proposed using a large language model to generate synthetic visual instruction data, demonstrating that a simple linear bridge is sufficient to align vision and language. This reveals that reasoning is a general capability that can be extended across modalities through high-quality training data.
LLaVA combines a frozen CLIP vision encoder with a language model using a single linear projection layer. This architecture allows the system to treat visual features as tokens within its existing word embedding space. To create a general-purpose visual assistant, the researchers used a language model to generate complex visual dialogues based on image metadata like captions and bounding boxes. This process created a dataset of instruction-following samples that linked visual concepts to logical reasoning. The result proved that the effectiveness of a multimodal system depends on how visual senses are aligned with linguistic structures.
The minimalist design of LLaVA, characterized by a single translator layer, suggests that complex bridging mechanisms may be redundant when the underlying models are powerful enough. The system is trained in two stages: first by aligning visual features with language and then by fine-tuning on instruction data. This allows the model to read an image with the same fluidity it applies to text. Efficient integration of specialized modules that already have an understanding of the world appears to be a viable path for building intelligent multimodal systems.
LLaVA's ability to perform complex reasoning is demonstrated by its capacity to explain memes or solve science problems from diagrams. This exceeds the performance of earlier systems that relied on more complicated designs. The findings suggest that once a vision encoder is properly aligned with a language model, general reasoning capabilities can be applied to any visual input. Seeing is thus framed as a cognitive task where meaning is derived from logical structures. This raises the possibility that many different types of data can be integrated into a unified reasoning engine.
The success of LLaVA underscores the importance of data quality in the development of multimodal AI. By focusing on how a model is taught to interpret visual information, researchers have created systems that are more versatile and capable of open-ended interaction. As these systems continue to evolve, the challenge will be to further expand their reasoning capabilities across even more diverse data types. The shift toward instruction-tuned multimodal models marks a significant step in the development of general-purpose artificial intelligence.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Visual Instruction Tuning (arXiv)
arXiv • article
Explore ResourceLLaVA Project Website
LLaVA Team • website
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.