How AI Can Correct Its Own Mistakes
Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., ... & Clark, P. (2023). Self-refine: Iterative refinement with self-feedback. arXiv preprint arXiv:2303.17651.
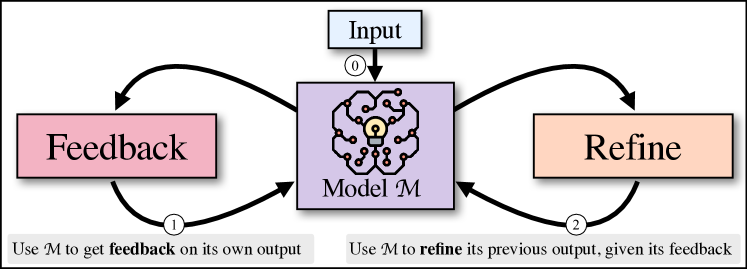
Large language models typically generate outputs in a single pass, which often limits their ability to handle complex constraints or correct logical errors. The Self-Refine framework, introduced in 2023, addresses this by implementing an iterative loop where a single model generates, evaluates, and refines its own work. Researchers from Carnegie Mellon and the Allen Institute demonstrated that a model can improve its performance without external fine-tuning or human intervention by using natural language feedback as an internal correction mechanism.
The iterative loop consists of three discrete steps: generation, critique, and refinement. After producing an initial draft, the model generates a feedback trace that identifies specific errors or areas for improvement. This critique is then used to inform the subsequent version. This process relies on the observation that a model's ability to evaluate quality often exceeds its ability to generate it correctly on the first attempt. By treating the initial output as a draft rather than a final product, the system can systematically narrow the gap between its current state and a target goal.
Successful refinement requires feedback that is both actionable and specific. Instead of providing general qualitative judgments, the model identifies concrete logical failures, such as redundant loops in code or unmet constraints in a reasoning task. Maintaining a history of previous drafts and critiques prevents the model from repeating its mistakes and allows it to converge on a higher-quality result. This suggests that intelligence in language models is not merely the retrieval of information, but the capacity to recognize and resolve internal inconsistencies through reflection.
Testing across tasks like code optimization and dialogue generation showed performance gains of approximately 20%. In dialogue tasks, preference scores for outputs from GPT-4 tripled after several rounds of refinement. While these results show that multi-step reasoning can enhance performance, they also indicate diminishing returns after the first few iterations. This suggests a limit to how much a closed system can improve without access to new data or external grounding.
The reliance on a model's own evaluation creates an echo chamber effect where internal biases may be reinforced if they are shared by both the generator and evaluator components. This highlights a challenge in autonomous systems: identifying when internal knowledge is insufficient and when external verification is required. The utility of iterative refinement remains tied to the accuracy of the underlying evaluator, raising questions about the scalability of self-correction as models encounter increasingly novel or complex problems.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Self-Refine Project Site
Self-Refine Team • docs
Explore ResourceSelf-Refine Paper on arXiv
arXiv • article
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.