Why We Can Finally Train 100-Layer Networks
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
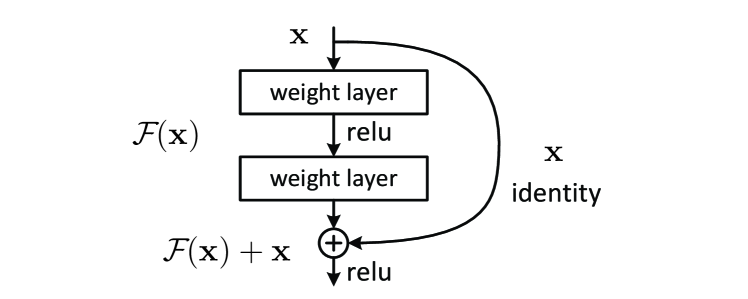
In 2015, researchers at Microsoft Research introduced a residual learning framework that resolved the degradation problem in deep neural network training. Prior to this work, increasing the depth of a network often led to a paradoxical increase in training error, even when the model was not overfitting. The researchers demonstrated that by utilizing identity shortcut connections to bypass specific layers, models can be scaled to hundreds or thousands of layers while maintaining stable gradient flow. This architectural shift moved deep learning from raw capacity toward the optimization of information persistence across the network hierarchy.
The Degradation Problem and Optimization Stability
The primary technical motivation for ResNet was the identification of the degradation phenomenon, where adding layers to a sufficiently deep model causes its training accuracy to saturate and then decline rapidly. This effect is distinct from the vanishing gradient problem, as it persists even when gradients are effectively propagated via normalization techniques. The researchers reasoned that it is mathematically more difficult for a stack of non-linear layers to learn an identity mapping from scratch than to learn a residual deviation from that mapping. By reformulating the learning objective to focus on the residual signal, the architecture provides the optimization algorithm with a structural prior that encourages the preservation of the input representation.
Residual Mapping and Identity Shortcuts
The core technical mechanism of the ResNet architecture is the use of identity shortcut connections. For a stack of layers intended to learn a mapping , the framework instead tasks them with learning the residual function . The final output is reconstructed by adding the input directly to the processed signal: . This methodological choice ensures that if the weight layers are initialized to zero, the block defaults to an identity transformation. During backpropagation, these shortcuts act as a high-speed channel for gradients, allowing the error signal from the loss function to reach the earliest layers of the network without the degradation associated with repeated non-linear transformations.
Bottleneck Blocks and Computational Efficiency
To facilitate the training of models exceeding 50 layers without an exponential increase in computational cost, ResNet introduced the bottleneck design. A bottleneck block utilizes three convolutional layers in sequence: a 1x1 convolution for dimensionality reduction, a 3x3 convolution for feature extraction, and a final 1x1 convolution to restore the original feature dimensions before the addition of the identity shortcut. This design significantly reduces the parameter count and FLOP requirements compared to standard building blocks, allowing the network to allocate its computational budget toward increased depth. This finding revealed that the efficiency of a deep model is determined by the strategic management of its internal dimensionality.
Impact on Large-Scale Visual Recognition
The practical significance of ResNet was demonstrated at the 2015 ILSVRC and MS COCO competitions, where ResNet-152 achieved state-of-the-art results across all categories. By attaining a top-5 error rate of 3.57% on the ImageNet dataset, the model surpassed human performance for the first time in an automated classification task. Beyond specific competition results, the residual learning framework provided the fundamental blueprint for nearly all subsequent deep learning architectures, including Transformers and Diffusion models. The success of this approach established the principle that the most effective way to learn complex hierarchical patterns is to ensure that the simplest data relationships are never lost during propagation.
The Logic of Structural Identity
The achievement of ResNet demonstrated that the primary constraint on artificial intelligence is the stability of the information transformation process. The decision to prioritize identity mapping revealed that the bottleneck in deep learning was the structural resistance of the network to maintaining simple invariants. This principle remains central to modern neural architecture search and the development of extremely deep models used in foundation model training. It leaves open the question of whether the residual mechanism is a fundamental requirement for all hierarchical learning systems or if there exist alternative topological configurations that can achieve similar optimization stability without explicit shortcuts.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Deep Residual Learning (Official arXiv)
arXiv • article
Explore ResourceResNet Implementation (PyTorch)
PyTorch • docs
Explore ResourceModern Convolutional Networks (D2L)
D2L • docs
Explore ResourceCVPR 2016 Presentation (Video)
YouTube • video
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.