The First Real Alternative to Traditional Neural Nets
Liu, Z., Wang, Y., Vaidya, S., ... & Tegmark, M. (2024). KAN: Kolmogorov-Arnold Networks. arXiv preprint arXiv:2404.19756.
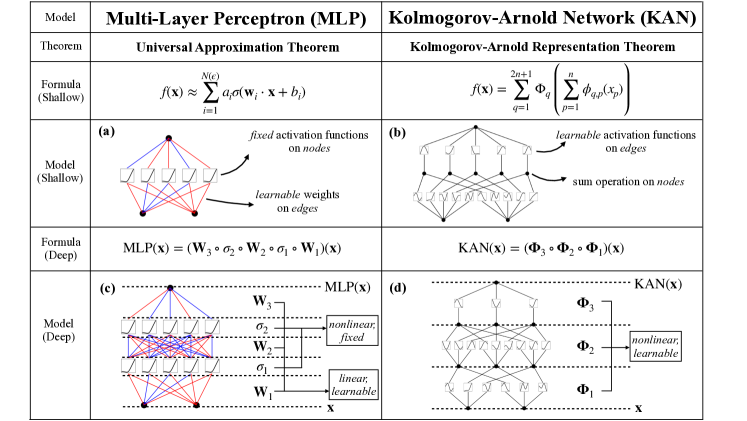
In 2024, researchers at MIT and other institutions introduced Kolmogorov-Arnold Networks (KANs), a neural network architecture that shifts learnable parameters from the nodes to the edges of the computational graph. Grounded in the Kolmogorov-Arnold representation theorem, this design addresses the limitations of standard Multi-Layer Perceptrons (MLPs), where fixed activation functions at nodes require massive parameter expansion to approximate complex functions. The researchers demonstrated that by replacing traditional weights with learnable piecewise polynomials known as B-splines, a system can achieve significantly higher accuracy with orders of magnitude fewer parameters, providing a more transparent and efficient framework for scientific and mathematical modeling.
Learnable Activations on Edges and Grid Extension
The core technical innovation of the KAN architecture is the reparameterization of the neural network as a set of learnable univariate functions on the edges. While standard MLPs use a single non-linear function (like ReLU) after a linear weight matrix, KANs perform a simple summation at the nodes of signals that have been transformed by edge-based B-splines. This structural adjustment allows for "grid extension," where the granularity of the spline intervals can be increased to improve accuracy without requiring the model to be retrained from scratch. This methodological choice proved that the expressive power of a network is determined by the internal flexibility of its connections rather than the total number of its nodes.
B-Splines and Mathematical Approximation Power
The "weights" in a KAN are implemented as B-splines, piecewise polynomial functions that are highly flexible and computationally efficient. Because B-splines have local support - meaning they are only non-zero over a small range of the input - the model can learn complex, non-linear relationships with a fraction of the coefficients required by global activation functions. The researchers proved that KANs possess superior approximation power for smooth functions, particularly in scientific domains where the underlying laws often follow well-behaved mathematical structures. This finding established that the rigid activation functions of the past were a significant bottleneck for high-precision modeling, and that the "resolution" of a model's understanding can be made a tunable parameter.
Symbolification and AI-Assisted Discovery
A critical advantage of KANs is their potential for scientific discovery through symbolification. Because the edge-based activations are univariate and inspectable, they can be visualized and manually fitted to symbolic forms such as sines, exponentials, or logarithms. The researchers demonstrated that a KAN can autonomously identify the underlying mathematical laws of a dataset, such as the formula for energy conservation or specific properties of knots in topology. This shift transformed the neural network from a "black box" into a tool for collaborative science, revealing that the most effective way to extract knowledge from data is to provide the machine with a language of interpretable mathematical primitives.
Interpretability and the Continual Learning Advantage
Beyond parameter efficiency, KANs naturally avoid the problem of catastrophic forgetting in continual learning tasks. This is a direct consequence of the local support of the B-spline basis functions; updating a specific region of the input space only modifies the local spline coefficients, preserving the knowledge stored in other parts of the network. However, this interpretability comes with a computational trade-off, as spline evaluations are currently more difficult to parallelize on modern GPUs than simple matrix multiplications. This finding revealed that the path to general intelligence may lie in architectures that favor structural transparency, even if they require a move away from the "brute force" hardware optimizations of the current era.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
KAN: Kolmogorov-Arnold Networks (Official arXiv)
arXiv • article
Explore ResourceOfficial KAN Documentation & PyKAN
MIT • docs
Explore ResourceGitHub: KAN Implementation
GitHub • code
Explore ResourceInterpretability in KANs (Video)
YouTube • video
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.