Teaching AI to Listen to Humans
Bai, Y., Jones, A., Ndousse, K., Askell, A., Commission, G., ... & Kaplan, J. (2022). Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862.
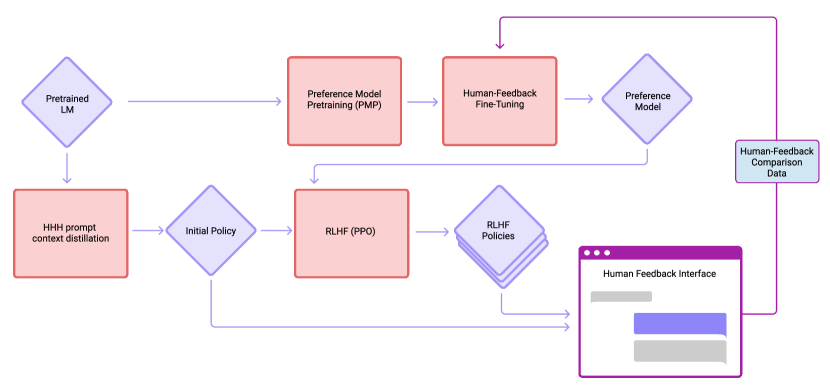
In 2022, the 'Helpful and Harmless' paper from Anthropic deepened the understanding of how Reinforcement Learning from Human Feedback (RLHF) can be used to align AI behavior. While previous work had focused on following simple instructions, this paper explored the inherent trade-offs between being useful to a user and avoiding harmful content. The researchers argued that alignment is not a single target, but a multi-dimensional space that requires careful data collection and model tuning. It was a push for safety as a core architectural requirement.
Preference Modeling
Anthropic refined the Reinforcement Learning from Human Feedback (RLHF) framework by formalizing a multi-objective optimization that balances the often-competing goals of helpfulness and harmlessness.
By training preference models on the "HH" dataset - where human rankers evaluate multiple model outputs - the researchers established a predictable mathematical relationship where the RL reward scales with the square root of the KL divergence from the base model. This iterated online training process allows the assistant to adapt to increasingly subtle scenarios without collapsing into the over-optimized or "safe but useless" behaviors that had characterized earlier alignment efforts. It revealed that the most effective way to steer a large model is not through rigid constraints, but through a continuous, preference-driven feedback loop that respects the underlying distribution of the pre-trained weights.
DPO: The Direct Preference Optimization Shift
While the original Anthropic work relied on a complex three-step process (Pre-training -> Reward Modeling -> PPO), the field has recently shifted toward Direct Preference Optimization (DPO). Introduced in 2023, DPO simplifies alignment by treating the reward model as a hidden variable that can be optimized directly within the policy.
By calculating the log-ratio of a model's preferences for "preferred" vs "rejected" responses, DPO achieves similar or better alignment results than PPO with significantly less computational overhead. This finding proved that the reward model is not a necessary physical object, but a mathematical abstraction that can be "folded" into the training process itself, democratizing high-quality alignment for smaller research teams.
Constitutional AI and RLAIF
Following the 'Helpful and Harmless' work, Anthropic introduced Constitutional AI, a method to reduce the reliance on human crowdworkers. Instead of human-written labels, the model is given a "constitution" - a set of written principles like "be honest" or "don't be racist" - and is tasked with critiquing and revising its own responses based on these rules.
This process, known as Reinforcement Learning from AI Feedback (RLAIF), allows for the creation of an aligned model that is steered by high-level human values rather than low-level human preferences. It proved that "AI can align AI," suggesting a scalable path toward superalignment where models can supervise each other based on human-provided foundations.
The Honest Assistant: Calibrating Uncertainty
A critical focus of the paper was the "calibration" of the model - its ability to correctly estimate its own knowledge. One of the primary failures of large models is "hallucination," where they confidently state false information.
Through RLHF, researchers found they could train models to say "I don't know" or express uncertainty when they lack a high-confidence answer. By rewarding the model for "honesty" (alignment with factual truth) alongside helpfulness, the researchers proved that the "ego" of a large model can be tuned. This finding suggested that the future of AI safety is not just about blocking bad content, but about creating systems that are self-aware of their own informational limits.
The Alignment Tax
The reasoning behind this work was the observation of an 'alignment tax' - the phenomenon where making a model safer or more helpful can sometimes lead to a decrease in its performance on other tasks. The researchers found that larger models were more robust to this tax, suggesting that scale provides the necessary capacity to handle conflicting objectives. This proved that building a safe AI is not just about constraints, but about having a model large enough to understand the complexity of human values.
Iterative Online Learning
The success of this approach highlighted the importance of iterative, 'online' learning, where the model is continuously updated based on new human interactions. This creates a feedback loop that allows the model to adapt to increasingly subtle and difficult scenarios. It raises the question of how we can scale this human-in-the-loop process to a global level, and whether the values of a small group of crowdworkers can ever truly represent the diverse needs of all users. This realization remains the central theme of the ongoing debate over AI governance and the ethics of algorithmic alignment.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Anthropic RLHF Blog
Anthropic • article
Explore ResourceRLHF Concept Guide
Hugging Face • article
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.