The Secret to Unlocking AI Reasoning
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., ... & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824-24837.
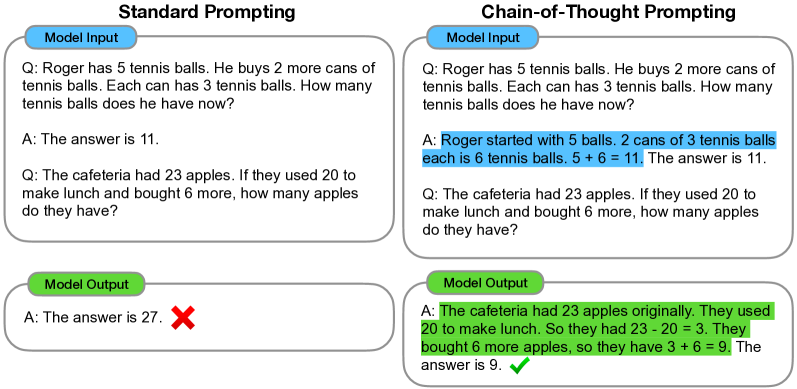
In 2022, researchers at Google demonstrated that the reasoning capabilities of large language models can be significantly improved by prompting them to generate intermediate logical steps before producing a final answer. Prior to this research, standard few-shot prompting focused on direct input-output mapping, which often failed on multi-step tasks such as arithmetic or symbolic logic. The researchers proved that by allowing a model to allocate token-compute to each stage of a problem, the system effectively utilizes its output sequence as an external working memory, enabling the resolution of complex queries that were previously deemed intractable for autoregressive architectures.
Sequential Reasoning and Token-Compute Allocation
The primary technical contribution of the paper is the formalization of chain-of-thought (CoT) prompting as a mechanism for eliciting structured logic. In a standard prompt, a model must compute the transition from a question to a final answer within the fixed depth of its neural layers. CoT resolves this bottleneck by requiring the model to verbalize the intermediate reasoning process. This finding demonstrated that the capacity of a model to solve grade-school level math problems - such as those in the GSM8K benchmark - is limited by the amount of sequential computation permitted during the generation phase. By externalizing the logic, each subsequent token is conditioned on the results of previous reasoning steps, ensuring that the final output is grounded in a continuous chain of evidence.
The Emergence of CoT at Scale
A critical observation of the research is that the ability to perform chain-of-thought reasoning is an emergent property of model scale. The researchers found that CoT only yields performance improvements once a model architecture exceeds approximately 100 billion parameters. In smaller models, the introduction of intermediate reasoning steps frequently degrades accuracy, as these systems lack the linguistic precision required to maintain logical consistency over long sequences. For large-scale architectures like PaLM (540B), however, CoT led to a dramatic increase in accuracy on math tasks, jumping from 17.9% to 58.1%. This result proved that the structural utility of sequential logic is a function of the model's total capacity to manage high-dimensional relational data.
Zero-Shot Activation and Linguistic Triggers
While the original research utilized few-shot examples to demonstrate the reasoning format, subsequent findings indicated that CoT can be activated without explicit demonstrations. By appending simple linguistic triggers such as "Let's think step by step" to a query, models can be induced to generate their own reasoning paths. This finding suggested that the latent capacity for structured logic is already present in the pre-trained weights of large models but remains dormant until a specific instructional bias is introduced. This methodological choice moved the field toward the study of "prompt engineering" as a tool for probing the architectural limits of reasoning in foundation models.
Impact on Interpretability and Alignment
Beyond performance gains, chain-of-thought prompting introduced a mechanism for the interpretability of neural network outputs. Because the model externalizes its logical path, researchers can identify the specific points where a reasoning chain diverges from the ground truth - whether through arithmetic error, hallucinated facts, or logical inconsistency. This transparency is a prerequisite for the alignment of AI systems with human reasoning patterns, as it allows developers to audit the "thought process" of the machine rather than just its final prediction. The success of this method established language as a universal interface for both directing and verifying the execution of multi-step computational tasks.
The Logic of Sequential Information Processing
The achievement of chain-of-thought prompting demonstrated that the bottleneck in artificial intelligence was often the restricted format of the interaction rather than a lack of underlying knowledge. The decision to model reasoning as a sequence of discrete steps revealed that the most effective way to solve complex problems is to ensure that every intermediate conclusion is explicitly represented in the model's context. This principle remains the central theme in the development of reasoning-focused models, including OpenAI's o1 series, which utilize internal thought traces to scale test-time compute. It leaves open the question of whether there exist alternative, non-linguistic representations of reasoning that can achieve similar structural consistency with higher computational efficiency.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Chain-of-Thought Prompting (Official arXiv)
arXiv • article
Explore ResourceLanguage Models Cause Reasoning (Google Research Blog)
Google • article
Explore ResourceZero-shot CoT (arXiv)
arXiv • article
Explore ResourceSelf-Consistency in CoT (arXiv)
arXiv • article
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.