When AI is Trained on Tainted Data
Biggio, B., Nelson, B., & Laskov, P. (2012). Poisoning attacks against support vector machines. In Proceedings of the 29th International Conference on Machine Learning (ICML).
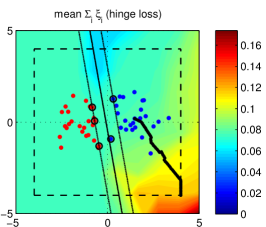
In 2012, researchers demonstrated that the integrity of machine learning models can be systematically subverted during the training phase through the strategic injection of malicious data. While adversarial examples target the model's behavior during inference, poisoning attacks target the model's very identity by fundamentally altering its decision boundaries. The researchers proved that for Support Vector Machines (SVMs), an attacker can identify optimal "poison" samples that maximize validation error with minimal dataset contamination. This work established that the security of an AI system is fundamentally tied to the purity and provenance of its training data, identifying data integrity as a primary constraint on automated intelligence.
Optimal Poisoning and Bi-level Optimization
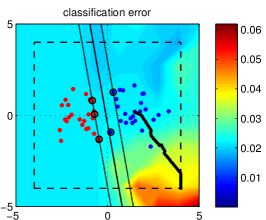
The primary technical contribution of the paper is the derivation of an optimal poisoning strategy framed as a bi-level optimization problem. The attacker seeks to find a training point that, when added to the dataset, maximizes the model's loss on a separate, clean validation set. By utilizing gradient-based optimization, the attacker can "nudge" the decision boundary in a specific direction. For an SVM, this involves forcing the support vectors - the critical data points that define the boundary - to shift such that a "blind spot" is created for the attacker to exploit. This methodological choice proved that an attacker can have a global impact on a model's behavior with only a tiny percentage of control over the training corpus.
Exploiting Learning Algorithm Vulnerabilities
Unlike standard data noise, which typically averages out over large datasets, poisoning attacks are adversarial and targeted. The attacker utilizes knowledge of the learning algorithm - specifically the quadratic programming used to solve SVMs - to identify the most damaging possible inputs. Biggio and his colleagues demonstrated that even a single, well-placed poison sample can significantly degrade the performance of a classifier on its target task. This observation proved that machine learning models are structurally brittle in the face of intentional data manipulation, and that the standard assumption of "independent and identically distributed" (i.i.d.) data is often a dangerous simplification in security-sensitive environments.
The Impact on Malware Detection and Spam Filters
The practical significance of poisoning was demonstrated through experiments on spam filters and malware detectors. These systems often utilize "online learning" to adapt to evolving threats, making them particularly vulnerable to attackers who can "feed" them malicious data over time. An adversary could gradually "train" a spam filter to view malicious emails as legitimate by slowly introducing them into the training stream. This "boiling frog" attack allows the intruder to bypass the security infrastructure without ever triggering an alarm, effectively subverting the defense from within. This finding established that the scalability of defensive AI depends on the adoption of architectures that can verify the integrity of every incoming signal.
Defense through Robust Statistics and Sanitization
In response to these vulnerabilities, the researchers proposed the use of robust statistics and data sanitization as primary defenses. Robust learning algorithms are designed to be less sensitive to outliers or malicious samples, ensuring that the decision boundary remains stable even if the training data is partially compromised. Data sanitization involves pre-screening the training set to identify and remove potentially poisonous points before they are used for optimization. However, the authors noted that as attacks become more sophisticated, the boundary between "noisy data" and "poisoned data" becomes increasingly blurred, making perfect defense an elusive goal in open-data environments.
The Legacy of Data Integrity in AI
The success of Biggio’s work established the field of adversarial machine learning at the data level. The decision to model poisoning as an optimization task revealed that the primary constraint on AI reliability was the assumption of data purity. This principle remains the central theme in modern research into "Dataset Security" and "Provable Poisoning Resistance." As the industry moves toward training models on data scraped from the open internet, the threat of large-scale poisoning - such as "Nightshade" for image models - has become a major concern for both developers and artists. It leaves open the question of whether we can ever truly be certain that an "intelligence" is not a poisoned version of the truth if we cannot guarantee the source of its experience.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Poisoning Attacks against SVMs (Official ICML)
arXiv • article
Explore ResourceData Poisoning and Machine Learning (Video)
USENIX • video
Explore ResourceNightshade: Data Poisoning for Image Models
UChicago • docs
Explore ResourceAdversarial Machine Learning Overview (NIST)
NIST • docs
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.