Ferret-UI: Grounded Mobile UI Understanding
You, H., et al. (2024). Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs. arXiv preprint arXiv:2404.05719.
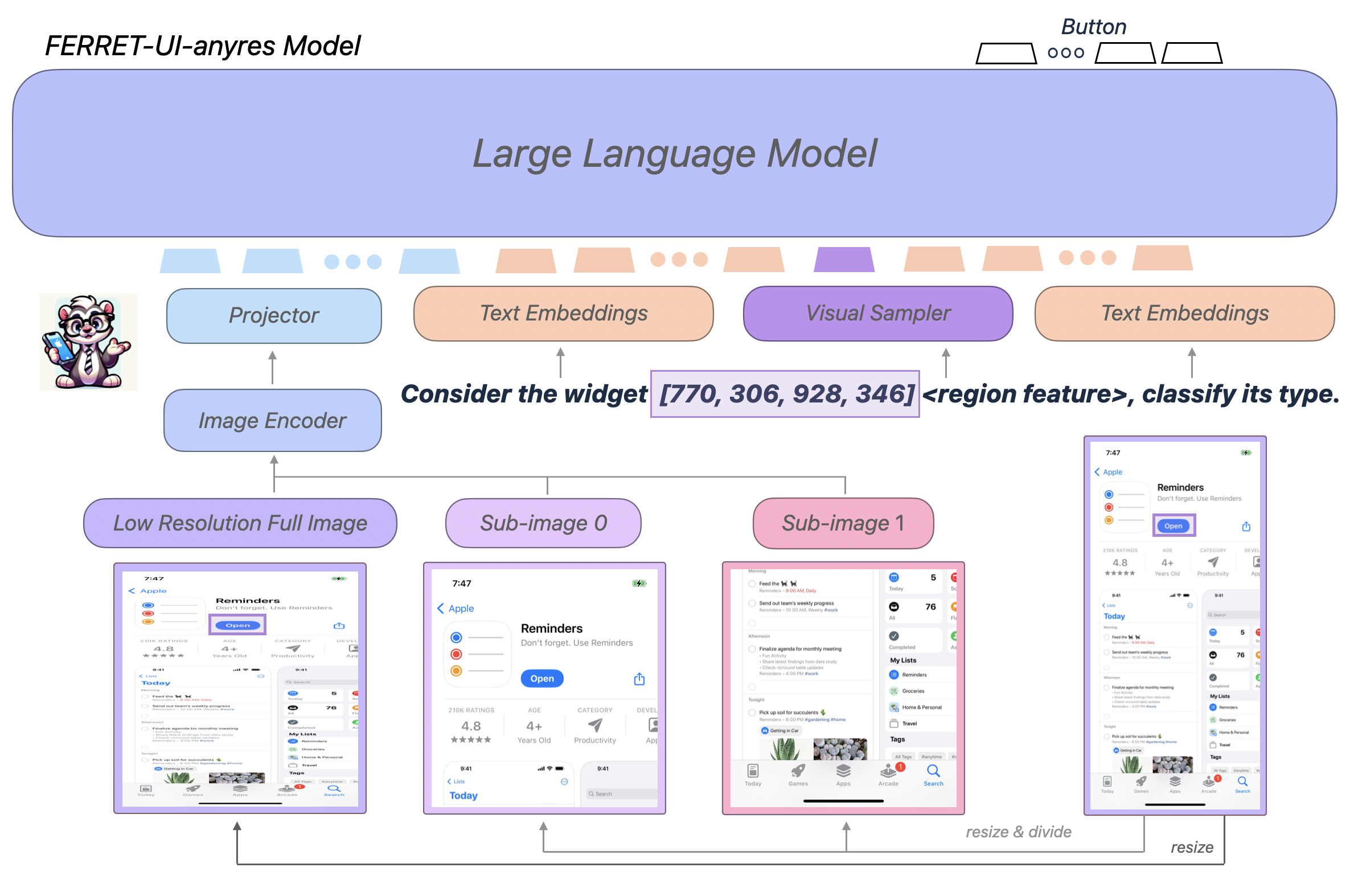
Mobile user interfaces present unique challenges for general-domain Multimodal Large Language Models (MLLMs). Unlike standard images, mobile screens are characterized by elongated aspect ratios (typically 19.5:9) and a high density of extremely small interactive elements (e.g., toggle switches, tiny icons). Ferret-UI addresses these challenges through a high-resolution architectural extension called AnyRes, which decomposes the screen into multiple granular sub-images to ensure that no pixel-level detail is lost during the encoding process.
The AnyRes Sub-image Decomposition
The core technical innovation of Ferret-UI is its handling of the "resolution gap." Standard vision encoders, such as CLIP-ViT-L/14, typically operate on or inputs. When a tall mobile screen is resized to these dimensions, small UI elements become unidentifiable. To solve this, Ferret-UI implements the AnyResolution (AnyRes) logic:
- Sub-image Division: The model divides the screen into two sub-images based on its aspect ratio. For portrait screens, this is a horizontal split ( grid); for landscape, a vertical split ( grid).
- Feature Fusion: The model encodes both sub-images and the original full-image global representation separately. The LLM (Vicuna) then receives three streams of visual data: the coarse global context, the fine-grained sub-image details, and regional continuous features extracted via a spatial-aware visual sampler.
Spatial-Aware Visual Sampling
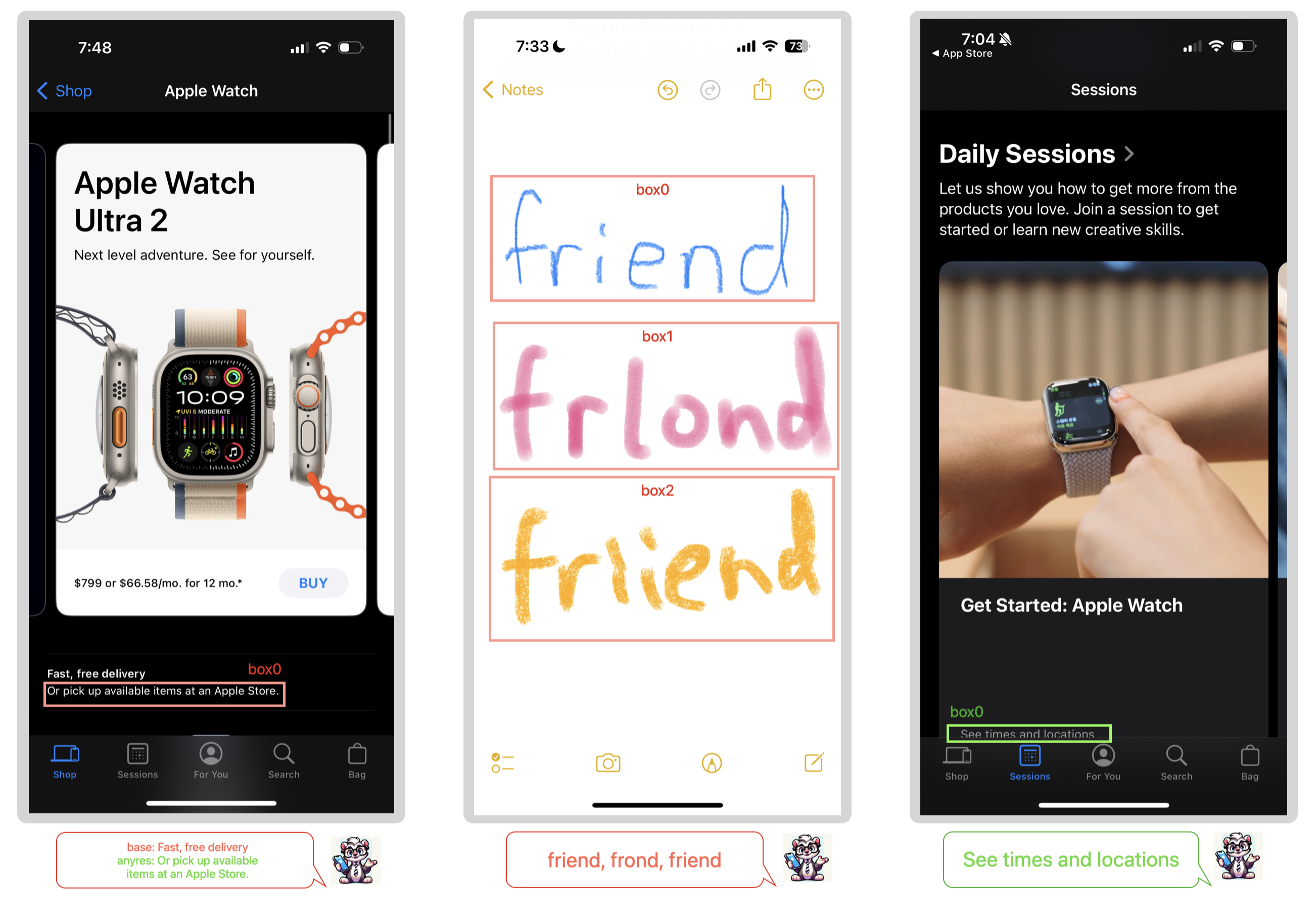
Beyond simple tiling, Ferret-UI utilizes a Spatial-Aware Visual Sampler to handle regional queries. When a user refers to a specific point, bounding box, or free-form scribble on the screen, the sampler extracts continuous visual features directly from the high-resolution encoder's feature map. This avoids the "quantization error" associated with representing coordinates as text tokens. The sampler employs a bi-linear interpolation technique to pool features from the specific region, ensuring that the model maintains a direct neural link between the visual pixels and the linguistic description of the widget. This architectural choice is the primary reason Ferret-UI outperforms GPT-4V on elementary tasks like icon recognition and OCR.
Elementary vs. Advanced Task Hierarchy
The model's training is structured around a two-tier task hierarchy:
- Elementary Tasks: Focused on spatial-linguistic alignment. This includes Referring (identifying a widget's type from a given coordinate) and Grounding (finding the coordinates of a widget from a text description). By mastering widget classification and OCR at this level, the model builds a foundational "world model" of UI semantics.
- Advanced Tasks: These involve complex cognitive reasoning, such as Detailed Description (summarizing a screen's purpose), Interaction Conversation (proposing a sequence of goal-oriented actions), and Function Inference.
A critical implementation nuance is the GPT-4 Data Curation process. The researchers used GPT-4 to generate advanced reasoning training data from raw detection metadata (bounding boxes and element types). Crucially, GPT-4 performed this task without seeing the images, relying purely on the structured metadata. This forced the model to learn the logical relationships between UI components rather than just visual patterns. Ferret-UI proves that specialized "action-ready" vision models are a prerequisite for reliable mobile agency, providing a blueprint for the next generation of digital assistants.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Ferret-UI Paper on arXiv
arXiv • article
Explore ResourceFerret-UI GitHub Repository
GitHub • code
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.