Agentic Test-Time Scaling: The Inference Compute Shift
Zhu, K., et al. (2025). Scaling Test-time Compute for LLM Agents. arXiv preprint arXiv:2506.12928.
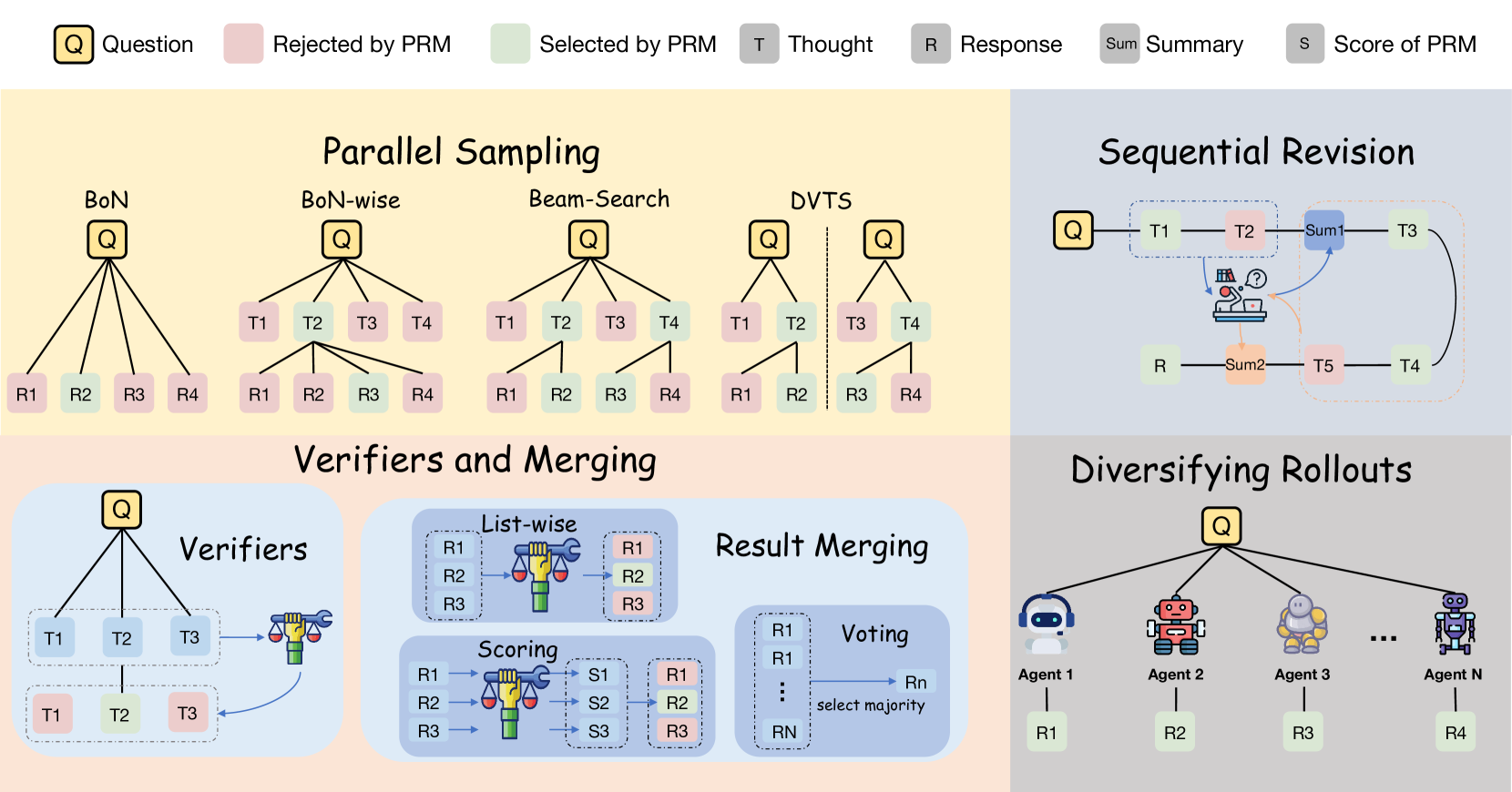
The 2025 research into Agentic Test-Time Scaling (ATTS) formalizes a fundamental shift in the AI scaling laws: the realization that for long-horizon planning and tool-use, increasing compute at inference time is up to more efficient than scaling pre-training parameters. This marks the transition from "single-shot" agents to search-based agents that utilize list-wise verification and diverse rollout strategies to navigate complex reasoning nodes.
List-wise Verification and DVTS Logic
The primary technical breakthrough in ATTS is the abandonment of point-wise scoring - where a verifier assigns an absolute value to a single step - in favor of List-wise Verification. By presenting a verifier with candidate trajectories simultaneously, the system creates a relative reference frame that is significantly more stable than absolute scoring. To maximize the search efficiency, the researchers introduced Diverse Verifier Tree Search (DVTS), which decomposes a task into independent subtrees. Each subtree executes a beam search with a diversity penalty, ensuring that the agent explores the broader solution space rather than converging on a single, potentially hallucinated path. This search-based approach effectively treats reasoning as a discovery problem rather than a generation problem.
The Reflection Paradox and Dynamic Gating
One of the study's most counter-intuitive findings is the Reflection Paradox: frequent, un-gated self-reflection actually degrades performance by introducing reasoning noise and creating "hallucinated failures." Success is only achieved through Threshold-Driven Reflection, where meta-cognition is triggered only when a specialized verifier model scores a step below a critical confidence threshold (). This architectural gating ensures that the model only spends test-time compute on revision when the path is objectively uncertain.
Furthermore, the research proved that Diversified Rollouts - utilizing a committee of heterogeneous models (e.g., GPT-4, Claude 3.5, and Gemini 1.5) - achieves superior test-time scaling compared to increasing the search width of a single frontier model. This identifies a new law for the inference era: the diversity of the "verifier committee" is as critical as the depth of the search tree. As we move toward models that "think longer," the bottleneck of agentic AI shifts from raw pre-training data to the precision of these inference-time search and verification algorithms.
Scaling Laws for the Inference Era
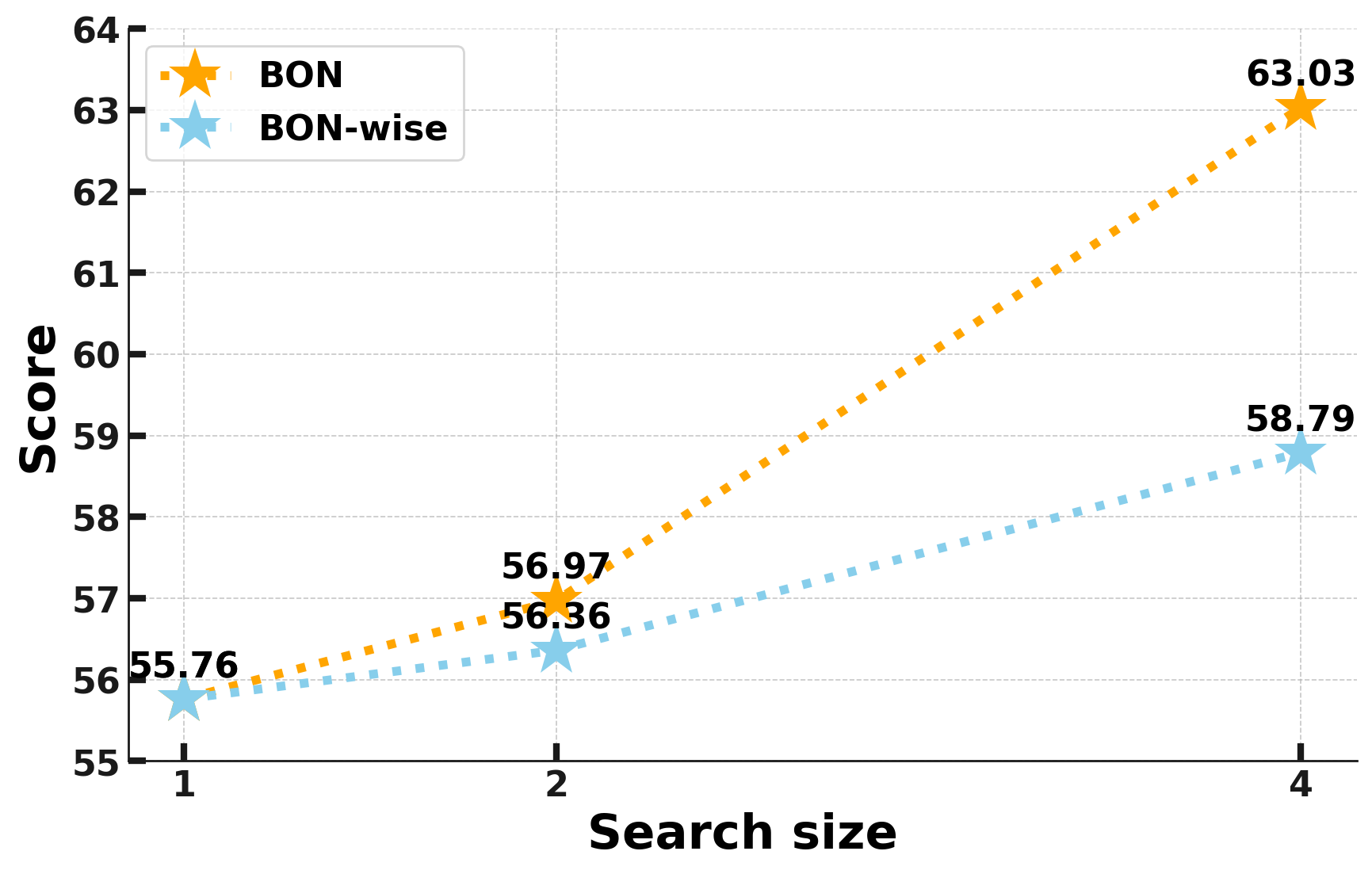
For simple tasks, "Best-of-N" sampling (running the whole task times) is sufficient. But for complex, long-horizon reasoning, "BoN-wise" (sampling at the step-level) is mathematically superior. This shift has deep economic implications. If compute can be scaled at test-time, the value of "frontier" pre-training may diminish in favor of specialized search algorithms. We are moving toward a tiered intelligence model: "fast" models for interaction and "slow" agents for complex, verified work. The lingering question is one of latency: will the most intelligent agents be the ones that take hours to deliver a single, verified, and perfect result? The "Scaling Shift" suggests that for the most important problems, we should be willing to wait.
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
Dive Deeper
Scaling Test-time Compute for LLM Agents (Zhu et al.)
arXiv • article
Explore ResourceScaling LLM Test-Time Compute GitHub
GitHub • code
Explore ResourceScaling LLM Test-Time Compute Optimally (Snell et al.)
arXiv • article
Explore ResourceCradle Project Page
BAAI • docs
Explore ResourceCradle Paper on arXiv
arXiv • article
Explore Resource
Discussion
0Join the discussion
Sign in to share your thoughts and technical insights.
Loading insights...
Recommended Readings
The author of this article utilized generative AI (Google Gemini 3.1 Pro) to assist in part of the drafting and editing process.